Ollama
npx @buildinternet/releases get ollamaSupport for the Codex App landed in v0.24.0, bringing OpenAI's desktop coding agent to local Ollama models.
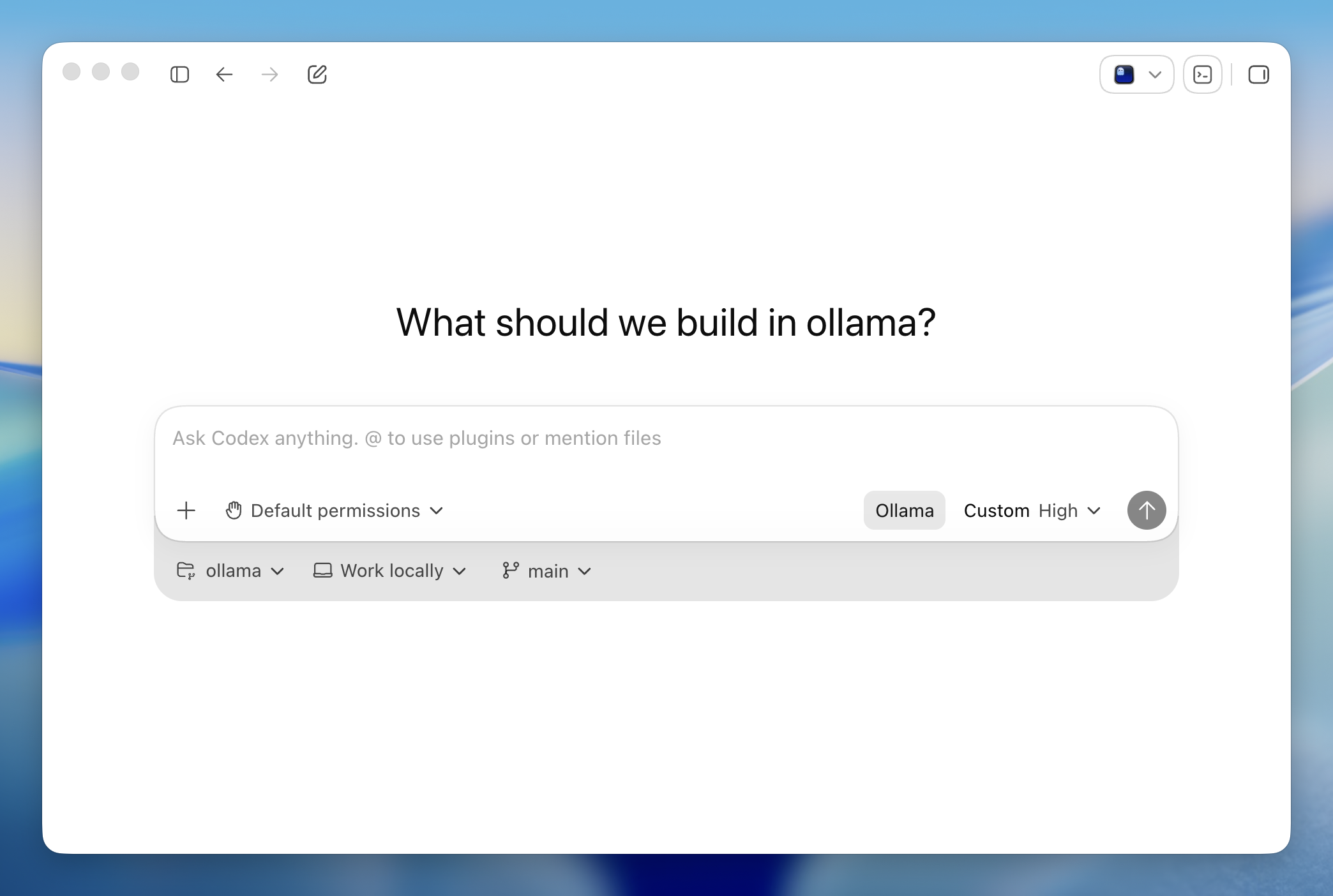
ollama launch gained a desktop coding environment. v0.24.0 added ollama launch codex-app, running OpenAI's Codex desktop app locally. It includes a built-in browser for loading local servers and annotating pages to request changes, a review mode for leaving inline comments, and parallel worktree support with built-in git functionality.
Speculative decoding arrived for Gemma 4 on Mac. v0.23.1 added Gemma 4 MTP support in the MLX runner, delivering over 2x speed gains on the gemma4:31b-coding-mtp-bf16 model for coding tasks.
/api/show caching cut integration latency. v0.23.2 cached /api/show responses, improving median latency by ~6.7x — noticeably faster load times for tools like VS Code.
The llama.cpp engine migration continued through the v0.30.x series. Releases from v0.30.3 through v0.30.9 iterated on the direct llama.cpp backend with steady updates to the underlying library. v0.30.3 added support for gemma4-12b; v0.30.5 fixed a floating-point exception crash on gemma4:12b; and v0.30.4 resolved a Windows cleanup issue that left llama-server processes running after shutdown.
MLX inference quality improved for Apple Silicon. v0.30.8 shipped MLX MTP cache improvements alongside fixes that harden linear and embedding layers against over-promotion, and decoupled prompt caching from context shift — a correctness fix that affects how long conversations are handled on Mac.
Windows tooling gaps closed. v0.30.7 switched the Hermes desktop app to use native Windows config paths, and the integration docs for Windows install were added in v0.30.8.