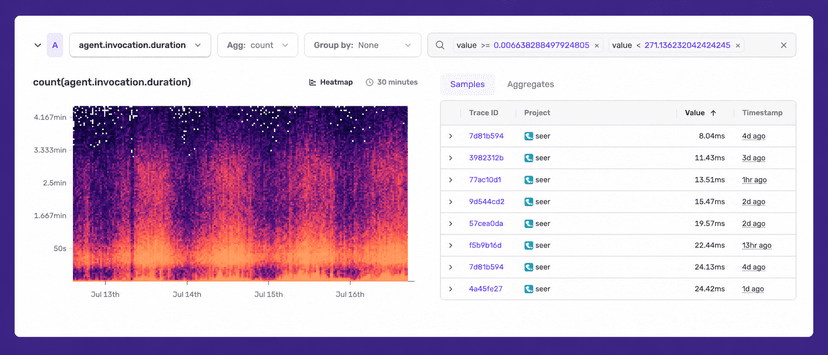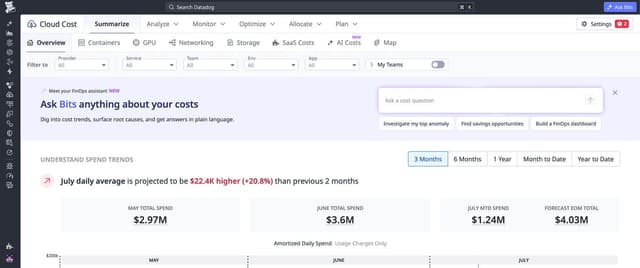
Heatmap visualization for Application Metrics
Heatmaps are a new visualization for Application Metrics that show both the distribution of metric values and how those distributions change over time, useful for spotting patterns like latency correlating with request bursts. Available in Custom Dashboards for the Application Metrics dataset.