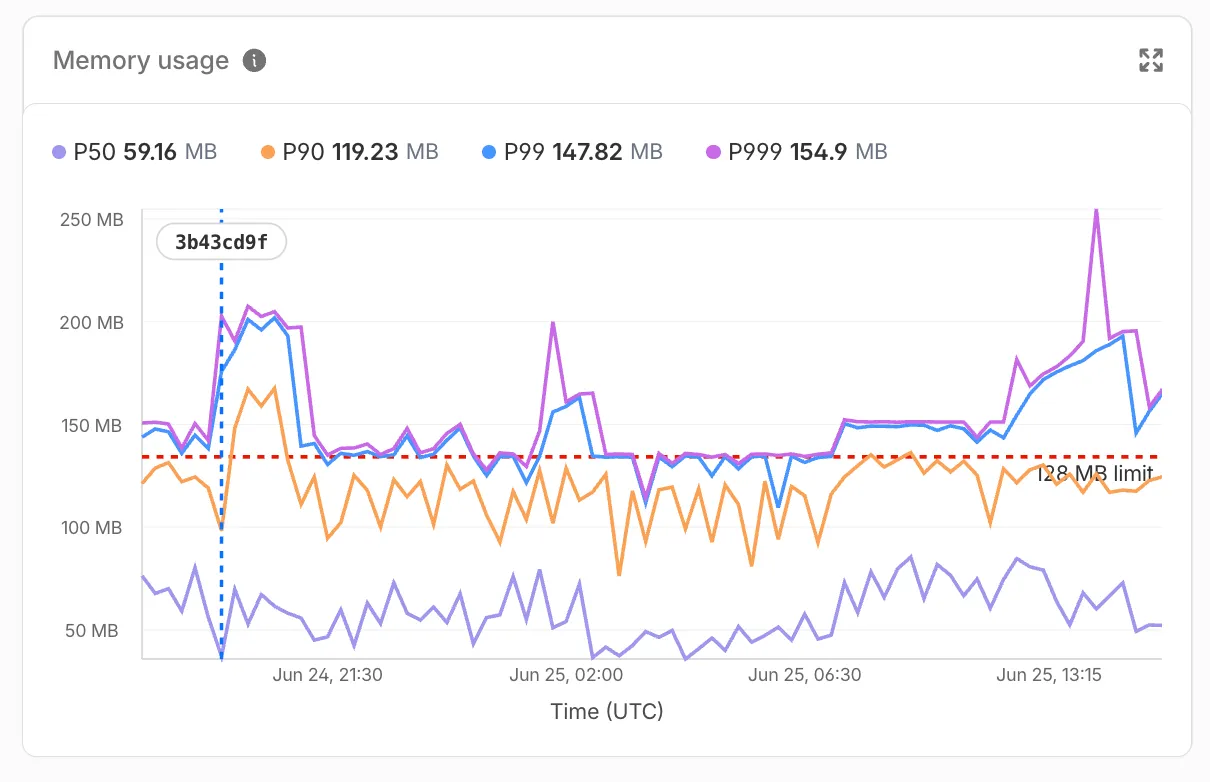
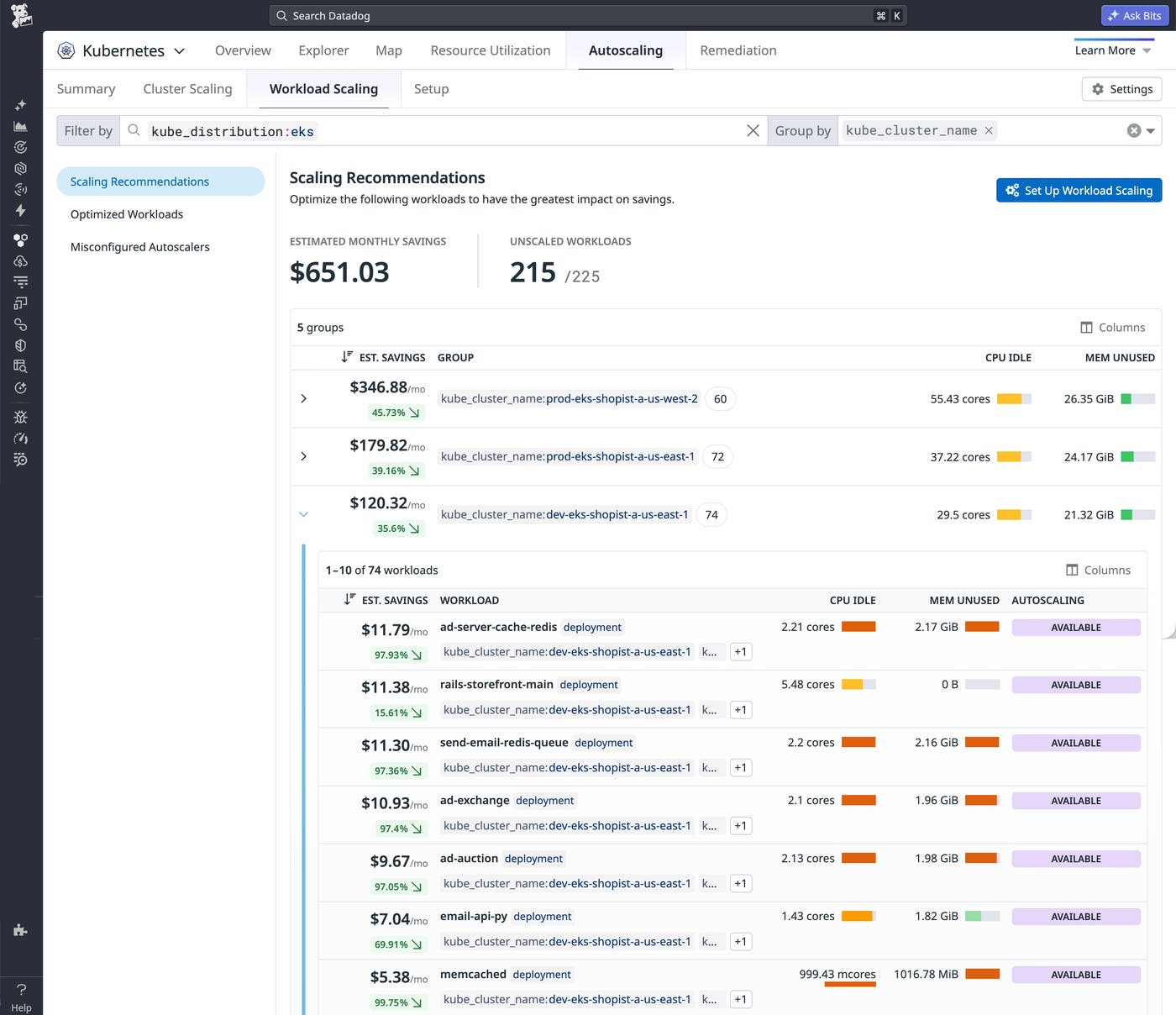
How We Found 7 TiB of Memory Just Sitting Around
How we saved 7 TiB of memory across our Kubernetes clusters by disabling namespace listwatching in Vector, reducing daemonset overhead and API server load at scale.
Fetched April 11, 2026
How we saved 7 TiB of memory across our Kubernetes clusters by disabling namespace listwatching in Vector, reducing daemonset overhead and API server load at scale.
Fetched April 11, 2026