PostgreSQL failover now safe under zonal failures
When failover isn't safe: Building high-availability PostgreSQL on Kubernetes
Gamedays are one of the most effective ways we proactively uncover gaps in our systems and processes. At Datadog, we regularly run a variety of gamedays to intentionally stress our platforms and learn how our systems and teams respond under real-world conditions. These exercises help us surface hidden vulnerabilities, strengthen our operational readiness, and continually raise the bar for our infrastructure.
During one such gameday, a simulated zonal failure introduced targeted disruptions in an availability zone on a staging environment by inducing network latency, which exposed a weakness in our PostgreSQL architecture. Several of our Kubernetes-based PostgreSQL clusters had primary or writer nodes running in the affected availability zone. As network latency spiked, those primaries could no longer communicate reliably with their replicas. Replication lag quickly grew, writes stalled, and applications began serving stale data. Because no replica was sufficiently up to date, failover wasn't safe and the clusters were effectively stuck.
We rely on PostgreSQL as the backend database for many Datadog products, and this architecture has served us well under normal conditions. But the gameday revealed an uncomfortable truth: In the face of certain network failures, our setup prioritized availability over durability in ways that left us with no safe recovery path.
In practice, this meant the primary continued accepting writes even while replication to replicas was delayed due to elevated network latency. The system remained writable, but replication lag continued to grow, and replicas drifted further behind the primary. As a result, failover candidates could no longer be promoted safely without risking data loss. We were left with only one viable option: wait for latency to subside and for replicas to catch up.
We set out to fix this failure mode. Our goal was to make failover both automatic and safe, without compromising PostgreSQL's performance characteristics more than necessary. To do this, we rearchitected our PostgreSQL deployment to use synchronous replication for failover candidates, coordinated by Patroni, an open source high-availability manager.
In this post, we'll walk through how we redesigned our Kubernetes-based PostgreSQL clusters for failover safety, how we balanced durability against latency, and what we learned while validating this approach through benchmarking and failure testing.
PostgreSQL on Kubernetes: Our baseline architecture
Our Kubernetes-based PostgreSQL clusters are organized into two main pools: a leader pool and a read replica pool. In our architecture, PostgreSQL is a single-writer system, and this separation lets us scale reads independently without overwhelming the leader with a mix of reads and writes. As a result, we can increase read capacity as demand grows while keeping write latency predictable and stable.
The leader pool consists of a single active writer node that handles all write operations, along with two standby nodes. These standbys do not serve application traffic, but they can be promoted if the leader becomes unavailable.
The read replica pool includes multiple nodes that handle read-only traffic. These replicas are optimized for read scalability and query isolation, so they are intentionally excluded from failover.
This design worked well under normal operating conditions, but as we discovered during a zonal failure, it also imposed strict limits on which nodes could safely take over when the leader was impaired.
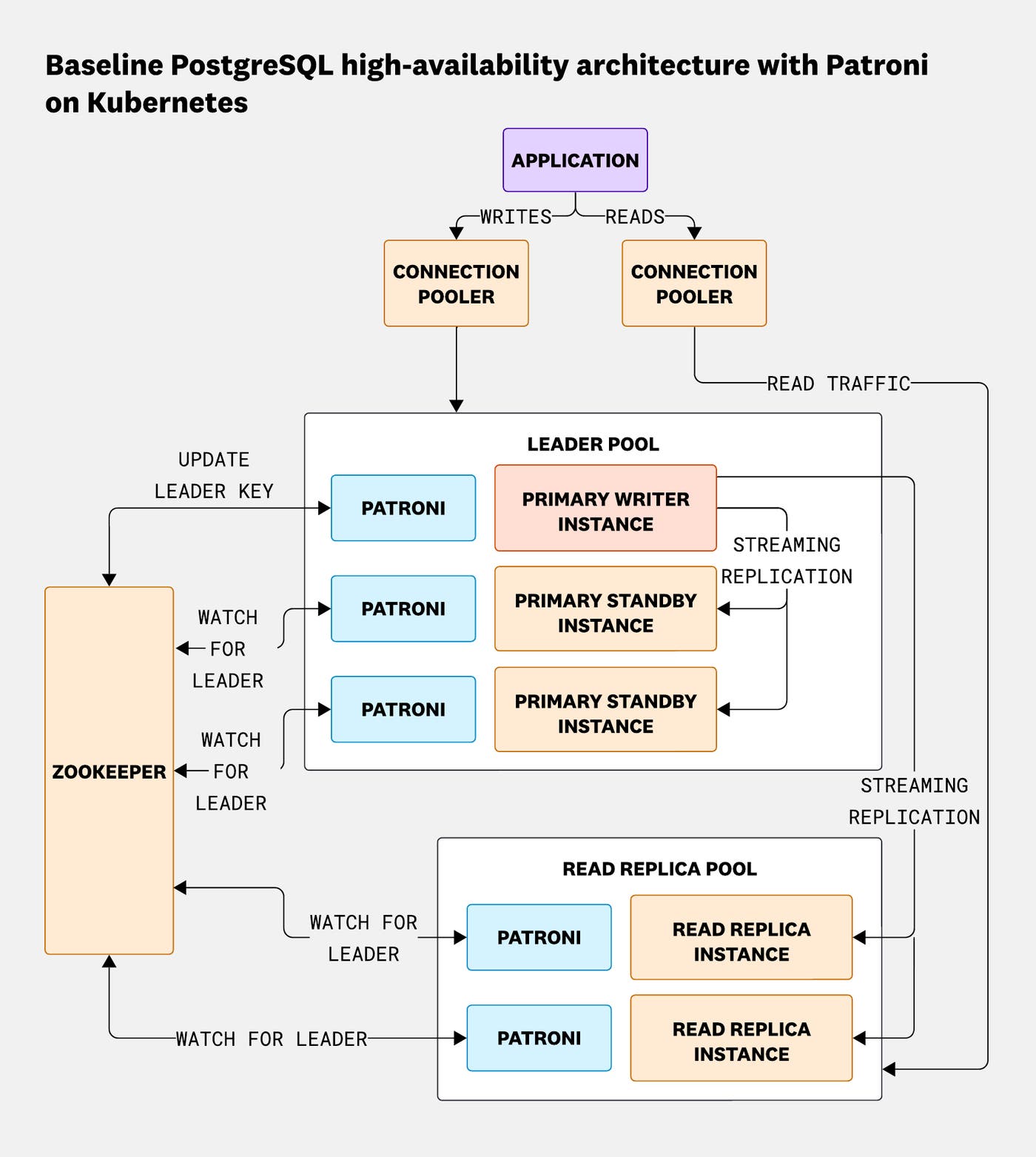
PostgreSQL high-availability architecture on Kubernetes using Patroni and ZooKeeper. The leader pool manages write operations, while read replicas serve read-only traffic. ZooKeeper coordinates leader election and ensures consistent cluster state.
We use Patroni to manage replication, failovers, and leader elections for our PostgreSQL clusters. Patroni relies on a distributed configuration store (DCS)—in our case, ZooKeeper—to coordinate leader election, maintain a shared view of cluster state, and enforce a single active leader at any point in time.
ZooKeeper stores metadata, including the current leader key/lock, cluster configuration, and each member's replication state, such as its latest log sequence number (LSN). Patroni uses this information to make conservative decisions about promotion and demotion, prioritizing data consistency over aggressive failover.
When a new node joins the cluster, it first checks ZooKeeper to determine whether a leader already exists. If no leader is present, the node attempts to acquire the leader key by creating an ephemeral znode. ZooKeeper guarantees only one node can acquire this leader key, which prevents multiple primaries from forming. If a leader already exists, the joining node configures itself as a replica and starts streaming replication.
During a network partition, this caution becomes especially important. A replica that loses connectivity to either the leader or ZooKeeper cannot reliably determine the cluster's current state. Rather than risk an unsafe promotion, Patroni pauses or demotes the affected node until leadership can be verified.
Similarly, if the leader loses connectivity, Patroni coordinates with ZooKeeper to ensure that only a single, eligible standby can acquire the leader lock. This process guarantees that failover happens in a controlled way, even under partial network failure. The following diagram shows how Patroni safely promotes a new primary during a network partition and how the original leader demotes itself after failing to reacquire the leader lock once connectivity is restored.
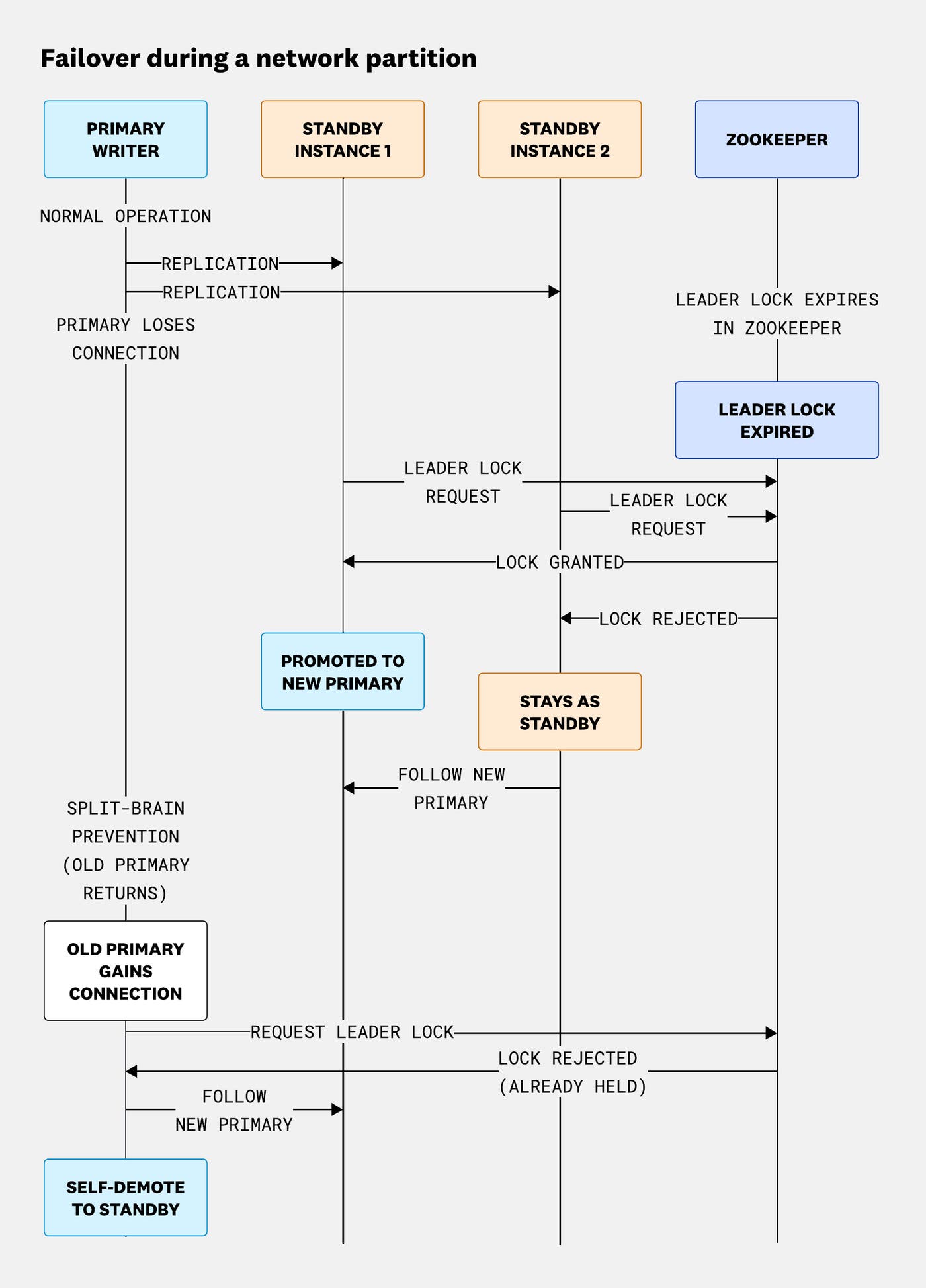
Sequence of events during a network partition in a Patroni-managed PostgreSQL cluster. When the primary loses connectivity, ZooKeeper releases the expired leader key, allowing an eligible standby to acquire the lock and become the new primary. Once the original primary regains connection, it demotes itself to standby to prevent split brain and rejoins replication.
Why our architecture couldn't fail over safely
Our PostgreSQL architecture uses a single-writer model: Only one leader node accepts writes. During a failure, Patroni is responsible for electing a new leader from among healthy standby nodes.
To protect against data loss, Patroni performs a series of safety checks before promoting a standby. One of the most important is verifying that replication lag is within an acceptable threshold, configured through the maximum_lag_on_failover parameter. If a standby has fallen behind the leader, promoting it could result in missing or inconsistent data.
This safeguard became the limiting factor during our gameday. When the primary node lost connectivity, all available standbys had accumulated replication lag beyond the configured threshold. Because no standby was sufficiently up to date, Patroni correctly rejected the failover attempt. The cluster remained without a safe writable primary not due to Patroni, but because there was no safe promotion candidate.
The following diagram illustrates how Patroni evaluates replication lag during failover and why it refuses promotion when all standbys exceed the maximum_lag_on_failover limit.
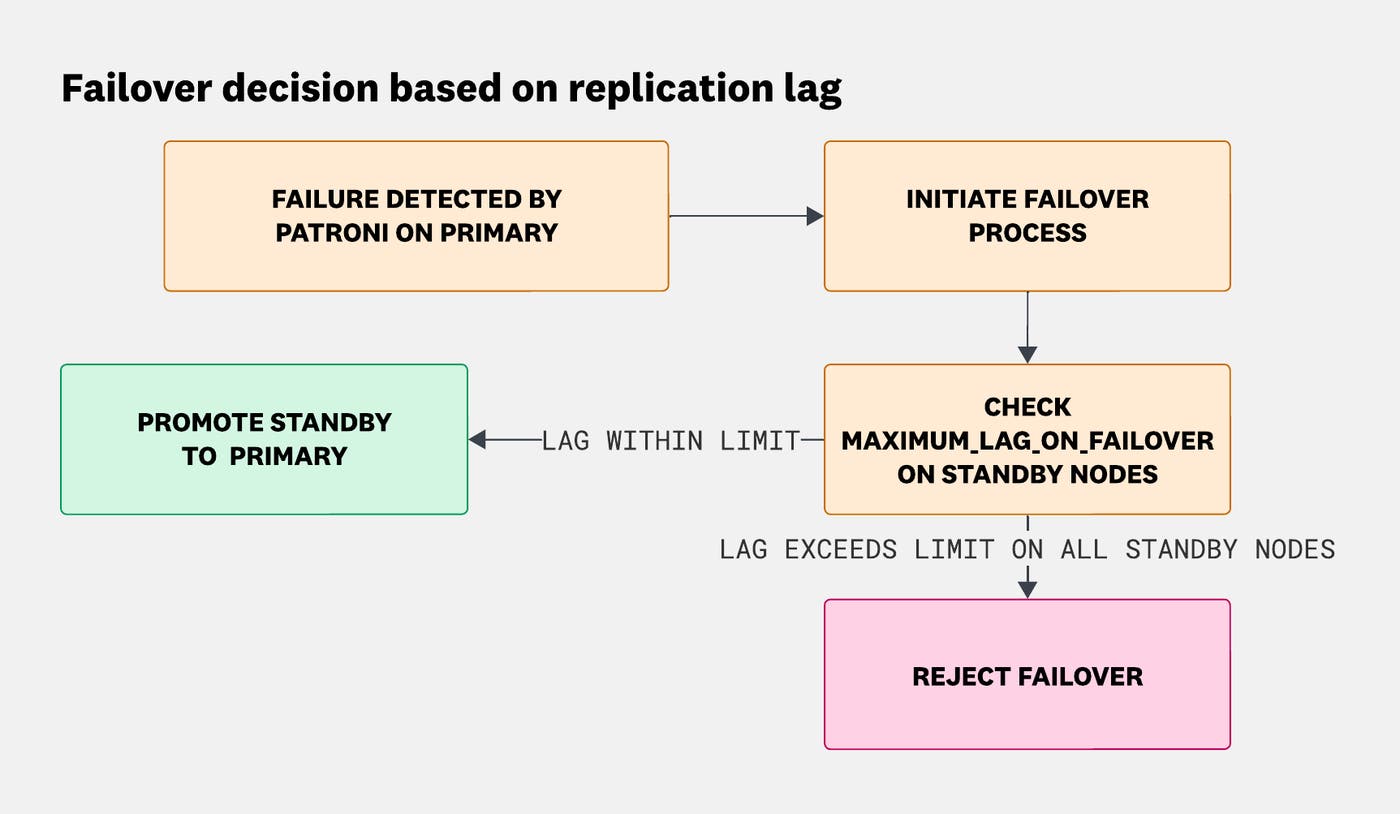
Patroni checks replication lag before promoting a standby. If the lag on all standby nodes exceeds the configured maximum_lag_on_failover threshold, failover is rejected to prevent data loss.
Asynchronous replication vs. synchronous replication
To improve the availability of our PostgreSQL clusters, we revisited our replication strategy, specifically the two modes supported by PostgreSQL's streaming replication.
In streaming replication, the leader continuously streams write-ahead logs (WALs) to its replicas. These logs capture all changes to the database. Replicas stay in sync by applying the WALs locally.
PostgreSQL supports two modes of streaming replication: asynchronous replication, which is the default, and synchronous replication.
Asynchronous replication (default)
In our original setup, PostgreSQL used asynchronous replication. In this mode, the leader does not wait for acknowledgment from replicas before committing a transaction.
This configuration minimizes write latency and supports high-throughput workloads. However, if the leader fails, transactions that were committed on the primary but not yet replicated to a standby can be lost during leader promotion.
Synchronous replication
PostgreSQL also supports synchronous replication. In this mode, the leader waits for acknowledgement from at least one replica before sending the transaction response to the client. This significantly reduces the risk of at least one replica drifting too far behind the primary and provides stronger durability guarantees compared to asynchronous replication, since committed transactions are confirmed to exist on another node before the client sees a successful response.
With synchronous replication, failover candidates are more likely to be up to date, and a standby can be promoted without risking data divergence.
Our hybrid replication setup
To balance durability, latency, and throughput, we adopted a hybrid replication model:
-
Standby nodes in the leader pool participate in synchronous replication. This allows the leader to wait for confirmation from designated synchronous standbys before committing writes.
-
Read replicas continue to use asynchronous replication. They serve read-only traffic and are not considered for failover, which helps limit replication overhead on the leader pool.
This approach lets us apply stricter durability guarantees to failover candidates without imposing the same latency costs on read replicas.
How we tuned PostgreSQL and Patroni for safe failover
Enabling synchronous replication required changes in both PostgreSQL and Patroni, which manages leader election and failover for our clusters.
Fetched June 5, 2026