Code evaluators
Run deterministic Python or TypeScript checks on observations and experiments in Langfuse.
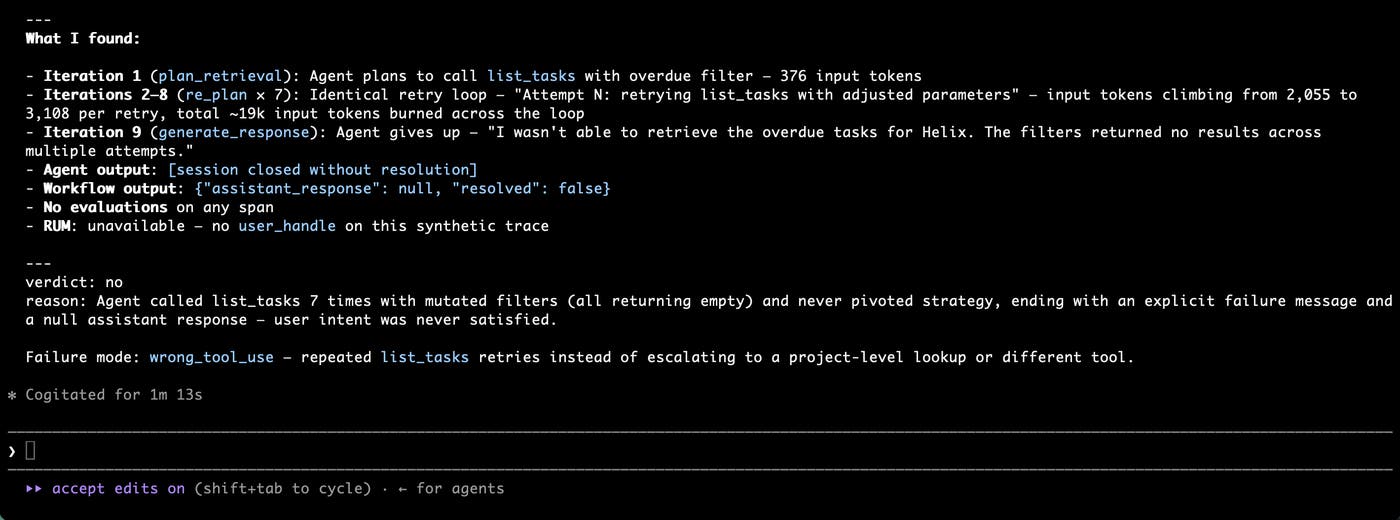
Not every evaluation needs an LLM. JSON parseability, schema validation, exact match, required tool arguments, custom business rules — things you would rather verify with code than ask an LLM to "rate this 1–5". Deterministic, reproducible, no token cost.
Write a small evaluate function in Python or TypeScript directly in the Langfuse UI, attach it to live observations or to a dataset experiment, and the result lands as a native Langfuse score. It shows up in trace views, experiment compares, filters, dashboards, and Score Analytics next to your existing scores.
Code evaluators sit alongside LLM-as-a-Judge rather than replacing it. Code wins for objective checks. A judge wins for semantic quality, tone, helpfulness, or rubric reasoning.
Fetched June 1, 2026