Defines search queries and a goal, and Firecrawl searches the entire web on a schedule, alerting via webhook or email when something new matches. The goal field filters results to decide which trigger alerts, with a plain-English explanation of relevance.
Firecrawl Changelog
Mon
Wed
Fri
JulAugSepOctNovDecJanFebMarAprMayJunJul
LessMore
Releases13Avg4/moVersionsv2.11.0 to v2.10
v2.11.0
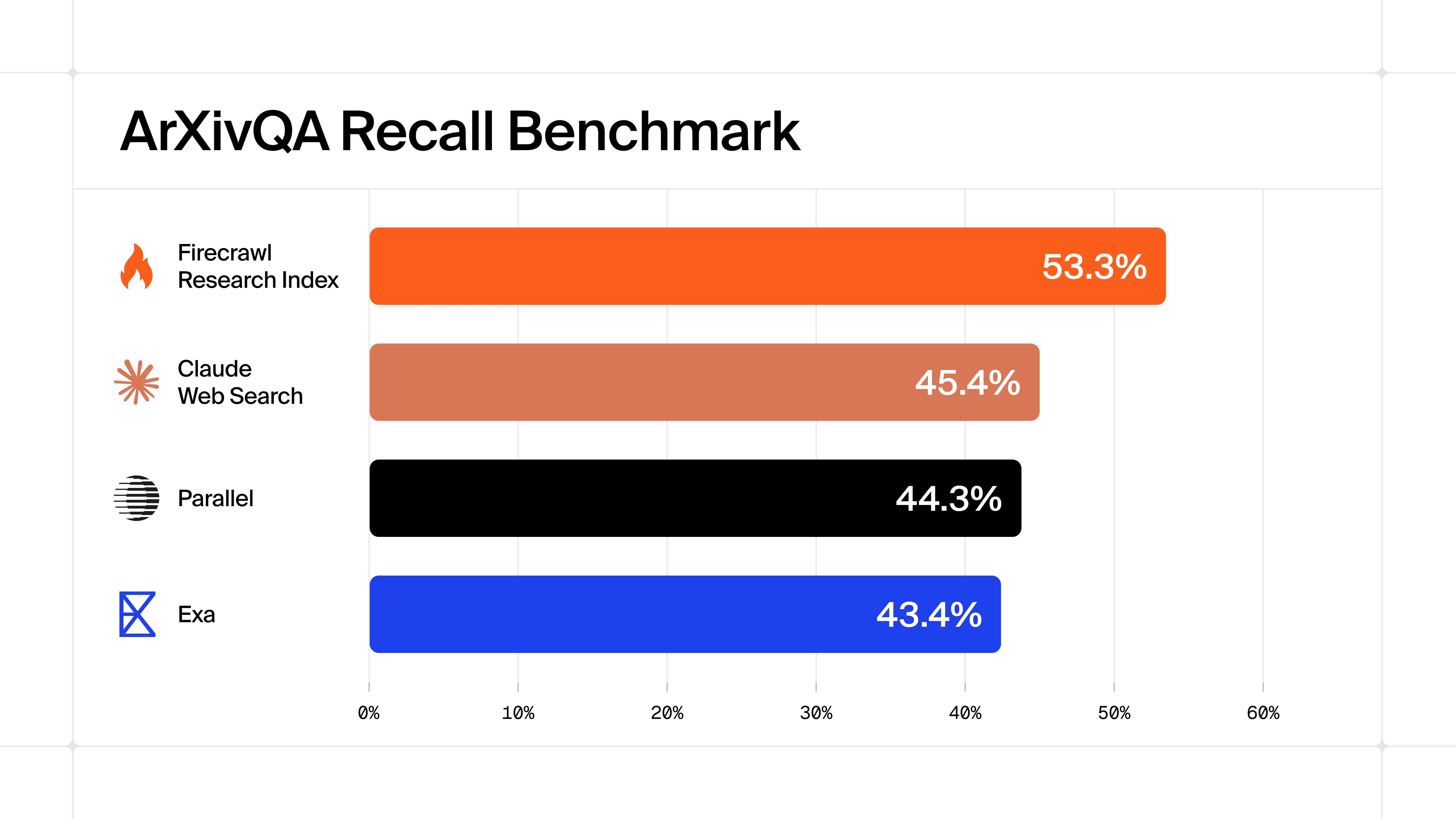
Firecrawl Research Index searches 3M+ arXiv papers and GitHub code, core endpoints can be accessed without an API key from official clients, and a new redactPII option strips personal data from scraped content. Also ships deterministicJson format and video discovery on any page.
A specialized search index for AI/ML research papers and code, achieving 53.3% recall on arXivQA versus 45.4% for the next best provider, with 3M+ papers and GitHub artifacts refreshed daily.
Enter a URL, describe what you want to track, and /monitor notifies your AI agent via webhook the moment pages or sites change. Use up to 90% fewer LLM tokens by only ingesting what actually changes.
v2.10.0
Firecrawl v2.10 ships a new /parse endpoint, Lockdown Mode, Question and Highlights formats, and four new official SDKs (Go, Ruby, PHP, .NET) - plus a long list of reliability and security fixes.
v2.10
Firecrawl v2.10 ships a new /parse endpoint, Lockdown Mode, Question and Highlights formats, and four new official SDKs (Go, Ruby, PHP, .NET) plus reliability and security fixes.
Highlights is a new format for /scrape that returns the exact sentences, code blocks, and table rows on a page that match your query, all while using up to 100x fewer tokens.
Question is a format for /scrape that returns high-quality, grounded answers from any web page using up to 100x fewer tokens.
Lockdown Mode is a cache-only option for /scrape that keeps security-sensitive requests inside Firecrawl. Set lockdown: true to serve results exclusively from Firecrawl's index, with zero data retention by default.
The /parse endpoint turns documents into clean, structured data for AI agents and RAG pipelines. Powered by a new Rust-based engine that's up to 5x faster, it works across PDFs, Word docs, spreadsheets, and more.
Firecrawl web-agent is an open framework for building AI agents that search, scrape, and interact with the web. Powered by the same architecture behind our /agent endpoint.
Fire-PDF is a Rust-based parsing engine that converts any PDF - scanned, text-based, or mixed - into structured markdown, up to 5x faster.
v2.9.0
Firecrawl v2.9.0 includes browser interaction via /interact, new scrape formats, smarter PDF handling, two new SDKs, and reliability fixes.
Introduce the new /interact endpoint that turns any scrape into a live browser session where agents can click, type, and navigate using natural language.
Full support for core endpoints including scrape, search, and crawl. Works with Maven, Gradle, and Java 17+.
New PDF parsing engine delivers 3x faster parsing and significantly improved reliability. Rebuilt in Rust, it automatically adapts to any PDF from clean text files to scanned reports and complex layouts.
Browser Sandbox gives agents a secure, fully managed browser environment for interactive web automation with no local setup, Chromium installs, or driver compatibility issues. Each session runs in an isolated, disposable sandbox that scales without infrastructure…
Significantly improved logo extraction accuracy for Branding Format v2, the endpoint for extracting brand identities from websites.
v2.8.0
Firecrawl v2.8.0 brings major improvements to agent workflows, developer tooling, and self-hosted deployments across the API and SDKs.
Bringing parallel processing to /agent, letting you batch hundreds or thousands of queries simultaneously. What took hours of sequential queries now completes in minutes with automatic failure handling and parallel execution.
Last Checked
1mo ago
Latest
Jul 1, 2026