v0.4.1
Large models training, Naive Pipeline Parallelism, peft Data Parallelism support and distributed training bug fixes
This release includes a set of features and bug fixes to scale up your RLHF experiments for much larger models leveraging peft and bitsandbytes.
Naive Pipeline Parallelism support
- Let's support naive Pipeline Parallelism by @younesbelkada in https://github.com/lvwerra/trl/pull/210
We introduce a new paradigm in trl , termed as Naive Pipeline Parallelism, to fit large scale models on your training setup and apply RLHF on them. This feature uses peft to train adapters and bitsandbytes to reduce the memory foot print of your active model
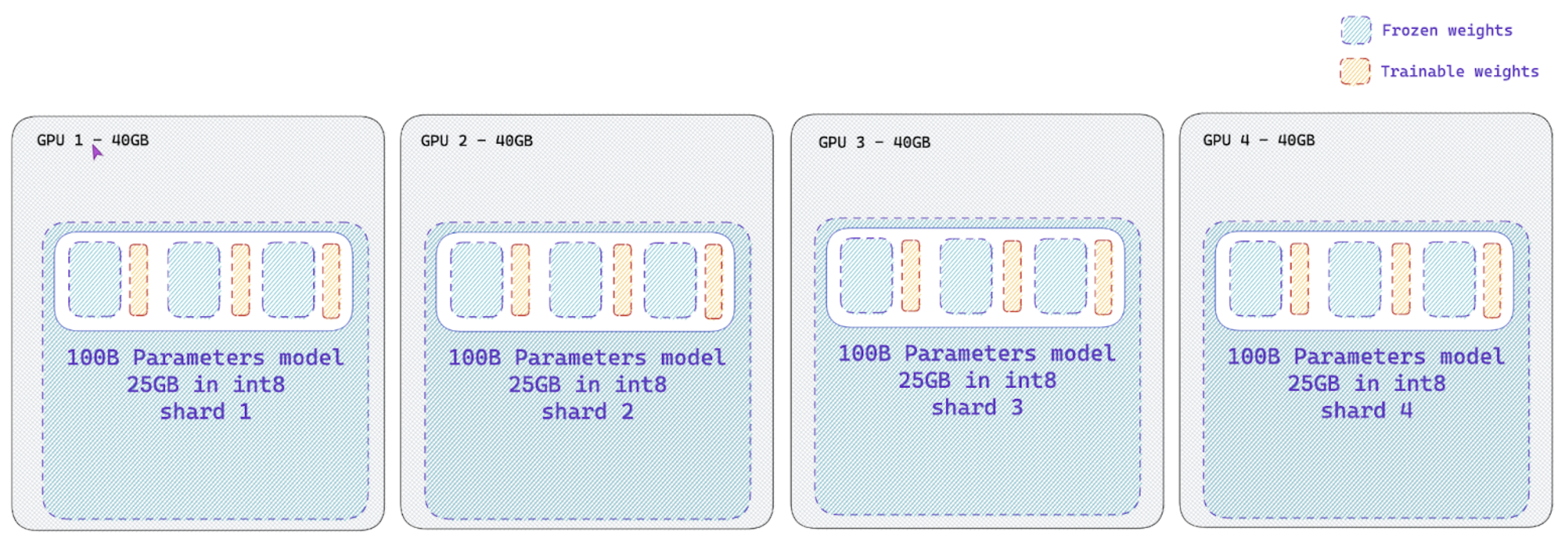
peft Data Parallelism support
- [
peft] Fix DP issues by @younesbelkada in https://github.com/lvwerra/trl/pull/221 - [
core] fix DP issue by @younesbelkada in https://github.com/lvwerra/trl/pull/222
There were some bugs with respect to peft integration and DP. This release includes the bug fixes to enable multi-GPU training using accelerate + DDP (DIstributed Data Parallel)
Memory optimization
Your training runs can be now much more memory efficient thanks to few tricks / bug fixes:
Now PPOConfig also supports the flag optimize_cuda_cache (set to False by default) to avoid increasing CUDA memory issues
- Grad accumulation and memory bugfix by @edbeeching in https://github.com/lvwerra/trl/pull/220
- adds a missing detach to the ratio by @edbeeching in https://github.com/lvwerra/trl/pull/224
Pytorch 2.0 fixes
This release also includes minor fixes related to PyTorch 2.0 release
- [
test] attempt to fix CI test for PT 2.0 by @younesbelkada in https://github.com/lvwerra/trl/pull/225
What's Changed
- adds sentiment example for a 20b model by @edbeeching in https://github.com/lvwerra/trl/pull/208
- Update README.md blog post link by @TeamDman in https://github.com/lvwerra/trl/pull/212
- spell mistakes by @k-for-code in https://github.com/lvwerra/trl/pull/213
- spell corrections by @k-for-code in https://github.com/lvwerra/trl/pull/214
- Small changes when integrating into H4 by @natolambert in https://github.com/lvwerra/trl/pull/216
New Contributors
- @TeamDman made their first contribution in https://github.com/lvwerra/trl/pull/212
- @k-for-code made their first contribution in https://github.com/lvwerra/trl/pull/213
Full Changelog: https://github.com/lvwerra/trl/compare/v0.4.0...v0.4.1
Fetched April 7, 2026