---
name: Tokenizers
slug: tokenizers
type: github
source_url: https://github.com/huggingface/tokenizers
organization: Hugging Face
organization_slug: hugging-face
total_releases: 100
latest_version: v0.22.2
latest_date: 2025-12-02
last_updated: 2026-04-19
tracking_since: 2019-12-03
canonical: https://releases.sh/hugging-face/tokenizers
organization_url: https://releases.sh/hugging-face
---
## Release v0.22.2
## What's Changed
Okay mostly doing the release for these PR:
* Update deserialize of added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1891
* update stub for typing by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1896
* bump PyO3 to 0.26 by @davidhewitt in https://github.com/huggingface/tokenizers/pull/1901
 Basically good typing with at least `ty`, and a lot fast (from 4 to 8x faster) loading vocab with a lot of added tokens and GIL free !?
* ci: add support for building Win-ARM64 wheels by @MugundanMCW in https://github.com/huggingface/tokenizers/pull/1869
* Add cargo-semver-checks to Rust CI workflow by @haixuanTao in https://github.com/huggingface/tokenizers/pull/1875
* Update indicatif dependency by @gordonmessmer in https://github.com/huggingface/tokenizers/pull/1867
* Bump node-forge from 1.3.1 to 1.3.2 in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1889
* Bump js-yaml from 3.14.1 to 3.14.2 in /bindings/node by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1892
* fix: used normalize_str in BaseTokenizer.normalize by @ishitab02 in https://github.com/huggingface/tokenizers/pull/1884
* [MINOR:TYPO] Update mod.rs by @cakiki in https://github.com/huggingface/tokenizers/pull/1883
* Remove runtime stderr warning from Python bindings by @Copilot in https://github.com/huggingface/tokenizers/pull/1898
* Mark immutable pyclasses as frozen by @ngoldbaum in https://github.com/huggingface/tokenizers/pull/1861
* DOCS: add `add_prefix_space` to `processors.ByteLevel` by @CloseChoice in https://github.com/huggingface/tokenizers/pull/1878
* Bump express from 4.21.2 to 4.22.1 in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1903
## New Contributors
* @MugundanMCW made their first contribution in https://github.com/huggingface/tokenizers/pull/1869
* @haixuanTao made their first contribution in https://github.com/huggingface/tokenizers/pull/1875
* @gordonmessmer made their first contribution in https://github.com/huggingface/tokenizers/pull/1867
* @ishitab02 made their first contribution in https://github.com/huggingface/tokenizers/pull/1884
* @Copilot made their first contribution in https://github.com/huggingface/tokenizers/pull/1898
* @ngoldbaum made their first contribution in https://github.com/huggingface/tokenizers/pull/1861
* @CloseChoice made their first contribution in https://github.com/huggingface/tokenizers/pull/1878
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.22.1...v0.22.2
# Release v0.22.1
Main change:
- Bump huggingface_hub upper version (#1866) from @Wauplin
- chore(trainer): add and improve trainer signature (#1838) from @shenxiangzhuang
- Some doc updates: c91d76ae558ca2dc1aa725959e65dc21bf1fed7e, 7b0217894c1e2baed7354ab41503841b47af7cf9, 57eb8d7d9564621221784f7949b9efdeb7a49ac1
## What's Changed
* Bump on-headers and compression in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1827
* Implement `from_bytes` and `read_bytes` Methods in WordPiece Tokenizer for WebAssembly Compatibility by @sondalex in https://github.com/huggingface/tokenizers/pull/1758
* fix: use AHashMap to fix compile error by @b00f in https://github.com/huggingface/tokenizers/pull/1840
* New stream by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1856
* [docs] Add more decoders by @pcuenca in https://github.com/huggingface/tokenizers/pull/1849
* Fix missing parenthesis in `EncodingVisualizer.calculate_label_colors` by @Liam-DeVoe in https://github.com/huggingface/tokenizers/pull/1853
* Update quicktour.mdx re: Issue #1625 by @WilliamPLaCroix in https://github.com/huggingface/tokenizers/pull/1846
* remove stray comment by @sanderland in https://github.com/huggingface/tokenizers/pull/1831
* Fix typo in README by @aisk in https://github.com/huggingface/tokenizers/pull/1808
* RUSTSEC-2024-0436 - replace paste with pastey by @nystromjd in https://github.com/huggingface/tokenizers/pull/1834
* Tokenizer: Add native async bindings, via py03-async-runtimes. by @michaelfeil in https://github.com/huggingface/tokenizers/pull/1843
## New Contributors
* @b00f made their first contribution in https://github.com/huggingface/tokenizers/pull/1840
* @pcuenca made their first contribution in https://github.com/huggingface/tokenizers/pull/1849
* @Liam-DeVoe made their first contribution in https://github.com/huggingface/tokenizers/pull/1853
* @WilliamPLaCroix made their first contribution in https://github.com/huggingface/tokenizers/pull/1846
* @sanderland made their first contribution in https://github.com/huggingface/tokenizers/pull/1831
* @aisk made their first contribution in https://github.com/huggingface/tokenizers/pull/1808
* @nystromjd made their first contribution in https://github.com/huggingface/tokenizers/pull/1834
* @michaelfeil made their first contribution in https://github.com/huggingface/tokenizers/pull/1843
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.3...v0.22.0rc0
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.3...v0.21.4
No change, the 0.21.3 release failed, this is just a re-release.
https://github.com/huggingface/tokenizers/releases/tag/v0.21.3
## What's Changed
* Clippy fixes. by @Narsil in https://github.com/huggingface/tokenizers/pull/1818
* Fixed an introduced backward breaking change in our Rust APIs.
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.2...v0.21.3
## What's Changed
This release if focused around some performance optimization, enabling broader python no gil support, and fixing some onig issues!
* Update the release builds following 0.21.1. by @Narsil in https://github.com/huggingface/tokenizers/pull/1746
* replace lazy_static with stabilized std::sync::LazyLock in 1.80 by @sftse in https://github.com/huggingface/tokenizers/pull/1739
* Fix no-onig no-wasm builds by @414owen in https://github.com/huggingface/tokenizers/pull/1772
* Fix typos in strings and comments by @co63oc in https://github.com/huggingface/tokenizers/pull/1770
* Fix type notation of merges in BPE Python binding by @Coqueue in https://github.com/huggingface/tokenizers/pull/1766
* Bump http-proxy-middleware from 2.0.6 to 2.0.9 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1762
* Fix data path in test_continuing_prefix_trainer_mismatch by @GaetanLepage in https://github.com/huggingface/tokenizers/pull/1747
* clippy by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1781
* Update pyo3 and rust-numpy depends for no-gil/free-threading compat by @Qubitium in https://github.com/huggingface/tokenizers/pull/1774
* Use ApiBuilder::from_env() in from_pretrained function by @BenLocal in https://github.com/huggingface/tokenizers/pull/1737
* Upgrade onig, to get it compiling with GCC 15 by @414owen in https://github.com/huggingface/tokenizers/pull/1771
* Itertools upgrade by @sftse in https://github.com/huggingface/tokenizers/pull/1756
* Bump webpack-dev-server from 4.10.0 to 5.2.1 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1792
* Bump brace-expansion from 1.1.11 to 1.1.12 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1796
* Fix features blending into a paragraph by @bionicles in https://github.com/huggingface/tokenizers/pull/1798
* Adding throughput to benches to have a more consistent measure across by @Narsil in https://github.com/huggingface/tokenizers/pull/1800
* Upgrading dependencies. by @Narsil in https://github.com/huggingface/tokenizers/pull/1801
* [docs] Whitespace by @stevhliu in https://github.com/huggingface/tokenizers/pull/1785
* Hotfixing the stub. by @Narsil in https://github.com/huggingface/tokenizers/pull/1802
* Bpe clones by @sftse in https://github.com/huggingface/tokenizers/pull/1707
* Fixed Length Pre-Tokenizer by @jonvet in https://github.com/huggingface/tokenizers/pull/1713
* Consolidated optimization ahash dary compact str by @Narsil in https://github.com/huggingface/tokenizers/pull/1799
* 🚨 breaking: Fix training with special tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1617
## New Contributors
* @414owen made their first contribution in https://github.com/huggingface/tokenizers/pull/1772
* @co63oc made their first contribution in https://github.com/huggingface/tokenizers/pull/1770
* @Coqueue made their first contribution in https://github.com/huggingface/tokenizers/pull/1766
* @GaetanLepage made their first contribution in https://github.com/huggingface/tokenizers/pull/1747
* @Qubitium made their first contribution in https://github.com/huggingface/tokenizers/pull/1774
* @BenLocal made their first contribution in https://github.com/huggingface/tokenizers/pull/1737
* @bionicles made their first contribution in https://github.com/huggingface/tokenizers/pull/1798
* @stevhliu made their first contribution in https://github.com/huggingface/tokenizers/pull/1785
* @jonvet made their first contribution in https://github.com/huggingface/tokenizers/pull/1713
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.1...v0.21.2rc0
## What's Changed
* Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693
* Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709
* Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708
* Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714
* Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/huggingface/tokenizers/pull/1701
* Fix typos by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1715
* Update documentation of Rust feature by @sondalex in https://github.com/huggingface/tokenizers/pull/1711
* Fix panic in DecodeStream::step due to incorrect index usage by @n0gu-furiosa in https://github.com/huggingface/tokenizers/pull/1699
* Fixing the stream by removing the read_index altogether. by @Narsil in https://github.com/huggingface/tokenizers/pull/1716
* Fixing NormalizedString append when normalized is empty. by @Narsil in https://github.com/huggingface/tokenizers/pull/1717
* 🚨 Support updating template processors by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1652. Removed in this release to keep backware compatibility temporarily.
* Update metadata as Python3.7 and Python3.8 support was dropped by @earlytobed in https://github.com/huggingface/tokenizers/pull/1724
* Add rustls-tls feature by @torymur in https://github.com/huggingface/tokenizers/pull/1732
## New Contributors
* @Dylan-Harden3 made their first contribution in https://github.com/huggingface/tokenizers/pull/1701
* @sondalex made their first contribution in https://github.com/huggingface/tokenizers/pull/1711
* @n0gu-furiosa made their first contribution in https://github.com/huggingface/tokenizers/pull/1699
* @earlytobed made their first contribution in https://github.com/huggingface/tokenizers/pull/1724
* @torymur made their first contribution in https://github.com/huggingface/tokenizers/pull/1732
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.0...v0.21.1
## What's Changed
* Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693
* Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709
* Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708
* Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714
* Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/huggingface/tokenizers/pull/1701
* Fix typos by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1715
* Update documentation of Rust feature by @sondalex in https://github.com/huggingface/tokenizers/pull/1711
* Fix panic in DecodeStream::step due to incorrect index usage by @n0gu-furiosa in https://github.com/huggingface/tokenizers/pull/1699
* Fixing the stream by removing the read_index altogether. by @Narsil in https://github.com/huggingface/tokenizers/pull/1716
* Fixing NormalizedString append when normalized is empty. by @Narsil in https://github.com/huggingface/tokenizers/pull/1717
* 🚨 Support updating template processors by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1652
* Update metadata as Python3.7 and Python3.8 support was dropped by @earlytobed in https://github.com/huggingface/tokenizers/pull/1724
* Add rustls-tls feature by @torymur in https://github.com/huggingface/tokenizers/pull/1732
## New Contributors
* @Dylan-Harden3 made their first contribution in https://github.com/huggingface/tokenizers/pull/1701
* @sondalex made their first contribution in https://github.com/huggingface/tokenizers/pull/1711
* @n0gu-furiosa made their first contribution in https://github.com/huggingface/tokenizers/pull/1699
* @earlytobed made their first contribution in https://github.com/huggingface/tokenizers/pull/1724
* @torymur made their first contribution in https://github.com/huggingface/tokenizers/pull/1732
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.0...v0.21.1rc0
## Release v0.21.0
## Release ~v0.20.4~ v0.21.0
* More cache options. by @Narsil in https://github.com/huggingface/tokenizers/pull/1675
* Disable caching for long strings. by @Narsil in https://github.com/huggingface/tokenizers/pull/1676
* Testing ABI3 wheels to reduce number of wheels by @Narsil in https://github.com/huggingface/tokenizers/pull/1674
* Adding an API for decode streaming. by @Narsil in https://github.com/huggingface/tokenizers/pull/1677
* Decode stream python by @Narsil in https://github.com/huggingface/tokenizers/pull/1678
* Fix encode_batch and encode_batch_fast to accept ndarrays again by @diliop in https://github.com/huggingface/tokenizers/pull/1679
We also no longer support python 3.7 or 3.8 (similar to transformers) as they are deprecated.
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.3...v0.21.0
## What's Changed
There was a breaking change in `0.20.3` for tuple inputs of `encode_batch`!
* fix pylist by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1673
* [MINOR:TYPO] Fix docstrings by @cakiki in https://github.com/huggingface/tokenizers/pull/1653
## New Contributors
* @cakiki made their first contribution in https://github.com/huggingface/tokenizers/pull/1653
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.2...v0.20.3
# Release v0.20.2
Thanks a MILE to @diliop we now have support for python 3.13! 🥳
## What's Changed
* Bump cookie and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1648
* Fix off-by-one error in tokenizer::normalizer::Range::len by @rlanday in https://github.com/huggingface/tokenizers/pull/1638
* Arg name correction: auth_token -> token by @rravenel in https://github.com/huggingface/tokenizers/pull/1621
* Unsound call of `set_var` by @sftse in https://github.com/huggingface/tokenizers/pull/1664
* Add safety comments by @Manishearth in https://github.com/huggingface/tokenizers/pull/1651
* Bump actions/checkout to v4 by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1667
* PyO3 0.22 by @diliop in https://github.com/huggingface/tokenizers/pull/1665
* Bump actions versions by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1669
## New Contributors
* @rlanday made their first contribution in https://github.com/huggingface/tokenizers/pull/1638
* @rravenel made their first contribution in https://github.com/huggingface/tokenizers/pull/1621
* @sftse made their first contribution in https://github.com/huggingface/tokenizers/pull/1664
* @Manishearth made their first contribution in https://github.com/huggingface/tokenizers/pull/1651
* @tinyboxvk made their first contribution in https://github.com/huggingface/tokenizers/pull/1667
* @diliop made their first contribution in https://github.com/huggingface/tokenizers/pull/1665
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.1...v0.20.2
## Release v0.20.1
## What's Changed
The most awaited `offset` issue with `Llama` is fixed 🥳
* Update README.md by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1608
* fix benchmark file link by @152334H in https://github.com/huggingface/tokenizers/pull/1610
* Bump actions/download-artifact from 3 to 4.1.7 in /.github/workflows by @dependabot in https://github.com/huggingface/tokenizers/pull/1626
* [`ignore_merges`] Fix offsets by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1640
* Bump body-parser and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1629
* Bump serve-static and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1630
* Bump send and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1631
* Bump webpack from 5.76.0 to 5.95.0 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1641
* Fix documentation build by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1642
* style: simplify string formatting for readability by @hamirmahal in https://github.com/huggingface/tokenizers/pull/1632
## New Contributors
* @152334H made their first contribution in https://github.com/huggingface/tokenizers/pull/1610
* @hamirmahal made their first contribution in https://github.com/huggingface/tokenizers/pull/1632
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.0...v0.20.1
## Release v0.20.0: faster encode, better python support
# Release v0.20.0
This release is focused on **performances** and **user experience**.
## Performances:
First off, we did a bit of benchmarking, and found some place for improvement for us!
With a few minor changes (mostly #1587) here is what we get on `Llama3` running on a g6 instances on AWS `https://github.com/huggingface/tokenizers/blob/main/bindings/python/benches/test_tiktoken.py` :

## Python API
We shipped better deserialization errors in general, and support for `__str__` and `__repr__` for all the object. This allows for a lot easier debugging see this:
```python3
>>> from tokenizers import Tokenizer;
>>> tokenizer = Tokenizer.from_pretrained("bert-base-uncased");
>>> print(tokenizer)
Tokenizer(version="1.0", truncation=None, padding=None, added_tokens=[{"id":0, "content":"[PAD]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":100, "content":"[UNK]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":101, "content":"[CLS]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":102, "content":"[SEP]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":103, "content":"[MASK]", "single_word":False, "lstrip":False, "rstrip":False, ...}], normalizer=BertNormalizer(clean_text=True, handle_chinese_chars=True, strip_accents=None, lowercase=True), pre_tokenizer=BertPreTokenizer(), post_processor=TemplateProcessing(single=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0)], pair=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0), Sequence(id=B, type_id=1), SpecialToken(id="[SEP]", type_id=1)], special_tokens={"[CLS]":SpecialToken(id="[CLS]", ids=[101], tokens=["[CLS]"]), "[SEP]":SpecialToken(id="[SEP]", ids=[102], tokens=["[SEP]"])}), decoder=WordPiece(prefix="##", cleanup=True), model=WordPiece(unk_token="[UNK]", continuing_subword_prefix="##", max_input_chars_per_word=100, vocab={"[PAD]":0, "[unused0]":1, "[unused1]":2, "[unused2]":3, "[unused3]":4, ...}))
>>> tokenizer
Tokenizer(version="1.0", truncation=None, padding=None, added_tokens=[{"id":0, "content":"[PAD]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":100, "content":"[UNK]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":101, "content":"[CLS]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":102, "content":"[SEP]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":103, "content":"[MASK]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}], normalizer=BertNormalizer(clean_text=True, handle_chinese_chars=True, strip_accents=None, lowercase=True), pre_tokenizer=BertPreTokenizer(), post_processor=TemplateProcessing(single=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0)], pair=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0), Sequence(id=B, type_id=1), SpecialToken(id="[SEP]", type_id=1)], special_tokens={"[CLS]":SpecialToken(id="[CLS]", ids=[101], tokens=["[CLS]"]), "[SEP]":SpecialToken(id="[SEP]", ids=[102], tokens=["[SEP]"])}), decoder=WordPiece(prefix="##", cleanup=True), model=WordPiece(unk_token="[UNK]", continuing_subword_prefix="##", max_input_chars_per_word=100, vocab={"[PAD]":0, "[unused0]":1, "[unused1]":2, ...}))
```
The `pre_tokenizer.Sequence` and `normalizer.Sequence` are also more accessible now:
```python
from tokenizers import normalizers
norm = normalizers.Sequence([normalizers.Strip(), normalizers.BertNormalizer()])
norm[0]
norm[1].lowercase=False
```
## What's Changed
* remove enforcement of non special when adding tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1521
* [BREAKING CHANGE] Ignore added_tokens (both special and not) in the decoder by @Narsil in https://github.com/huggingface/tokenizers/pull/1513
* Make `USED_PARALLELISM` atomic by @nathaniel-daniel in https://github.com/huggingface/tokenizers/pull/1532
* Fixing for clippy 1.78 by @Narsil in https://github.com/huggingface/tokenizers/pull/1548
* feat(ci): add trufflehog secrets detection by @McPatate in https://github.com/huggingface/tokenizers/pull/1551
* Switch from `cached_download` to `hf_hub_download` in tests by @Wauplin in https://github.com/huggingface/tokenizers/pull/1547
* Fix "dictionnary" typo by @nprisbrey in https://github.com/huggingface/tokenizers/pull/1511
* make sure we don't warn on empty tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1554
* Enable `dropout = 0.0` as an equivalent to `none` in BPE by @mcognetta in https://github.com/huggingface/tokenizers/pull/1550
* Revert "[BREAKING CHANGE] Ignore added_tokens (both special and not) … by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1569
* Add bytelevel normalizer to fix decode when adding tokens to BPE by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1555
* Fix clippy + feature test management. by @Narsil in https://github.com/huggingface/tokenizers/pull/1580
* Bump spm_precompiled to 0.1.3 by @MikeIvanichev in https://github.com/huggingface/tokenizers/pull/1571
* Add benchmark vs tiktoken by @Narsil in https://github.com/huggingface/tokenizers/pull/1582
* Fixing the benchmark. by @Narsil in https://github.com/huggingface/tokenizers/pull/1583
* Tiny improvement by @Narsil in https://github.com/huggingface/tokenizers/pull/1585
* Enable fancy regex by @Narsil in https://github.com/huggingface/tokenizers/pull/1586
* Fixing release CI strict (taken from safetensors). by @Narsil in https://github.com/huggingface/tokenizers/pull/1593
* Adding some serialization testing around the wrapper. by @Narsil in https://github.com/huggingface/tokenizers/pull/1594
* Add-legacy-tests by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1597
* Adding a few tests for decoder deserialization. by @Narsil in https://github.com/huggingface/tokenizers/pull/1598
* Better serialization error by @Narsil in https://github.com/huggingface/tokenizers/pull/1595
* Add test normalizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1600
* Improve decoder deserialization by @Narsil in https://github.com/huggingface/tokenizers/pull/1599
* Using serde (serde_pyo3) to get __str__ and __repr__ easily. by @Narsil in https://github.com/huggingface/tokenizers/pull/1588
* Merges cannot handle tokens containing spaces. by @Narsil in https://github.com/huggingface/tokenizers/pull/909
* Fix doc about split by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1591
* Support `None` to reset pre_tokenizers and normalizers, and index sequences by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1590
* Fix strip python type by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1602
* Tests + Deserialization improvement for normalizers. by @Narsil in https://github.com/huggingface/tokenizers/pull/1604
* add deserialize for pre tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1603
* Perf improvement 16% by removing offsets. by @Narsil in https://github.com/huggingface/tokenizers/pull/1587
## New Contributors
* @nathaniel-daniel made their first contribution in https://github.com/huggingface/tokenizers/pull/1532
* @nprisbrey made their first contribution in https://github.com/huggingface/tokenizers/pull/1511
* @mcognetta made their first contribution in https://github.com/huggingface/tokenizers/pull/1550
* @MikeIvanichev made their first contribution in https://github.com/huggingface/tokenizers/pull/1571
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.19.1...v0.20.0rc1
## What's Changed
* add serialization for `ignore_merges` by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1504
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.19.0...v0.19.1
## What's Changed
* chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442
* [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436
* Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1456
* Added ability to inspect a 'Sequence' decoder and the `AddedVocabulary`. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1443
* 🚨🚨 BREAKING CHANGE 🚨🚨: (add_prefix_space dropped everything is using prepend_scheme enum instead) Refactor metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1476
* Add more support for tiktoken based tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1493
* PyO3 0.21. by @Narsil in https://github.com/huggingface/tokenizers/pull/1494
* Remove 3.13 (potential undefined behavior.) by @Narsil in https://github.com/huggingface/tokenizers/pull/1497
* Bumping all versions 3 times (ty transformers :) ) by @Narsil in https://github.com/huggingface/tokenizers/pull/1498
* Fixing doc. by @Narsil in https://github.com/huggingface/tokenizers/pull/1499
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.2...v0.19.0
Bumping 3 versions because of this: https://github.com/huggingface/transformers/blob/60dea593edd0b94ee15dc3917900b26e3acfbbee/setup.py#L177
## What's Changed
* chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442
* [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436
* Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1456
* Added ability to inspect a 'Sequence' decoder and the `AddedVocabulary`. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1443
* 🚨🚨 BREAKING CHANGE 🚨🚨: (add_prefix_space dropped everything is using prepend_scheme enum instead) Refactor metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1476
* Add more support for tiktoken based tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1493
* PyO3 0.21. by @Narsil in https://github.com/huggingface/tokenizers/pull/1494
* Remove 3.13 (potential undefined behavior.) by @Narsil in https://github.com/huggingface/tokenizers/pull/1497
* Bumping all versions 3 times (ty transformers :) ) by @Narsil in https://github.com/huggingface/tokenizers/pull/1498
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.2...v0.19.0rc0
## What's Changed
Big shoutout to @rlrs for [the fast replace normalizers](https://github.com/huggingface/tokenizers/pull/1413) PR. This boosts the performances of the tokenizers:
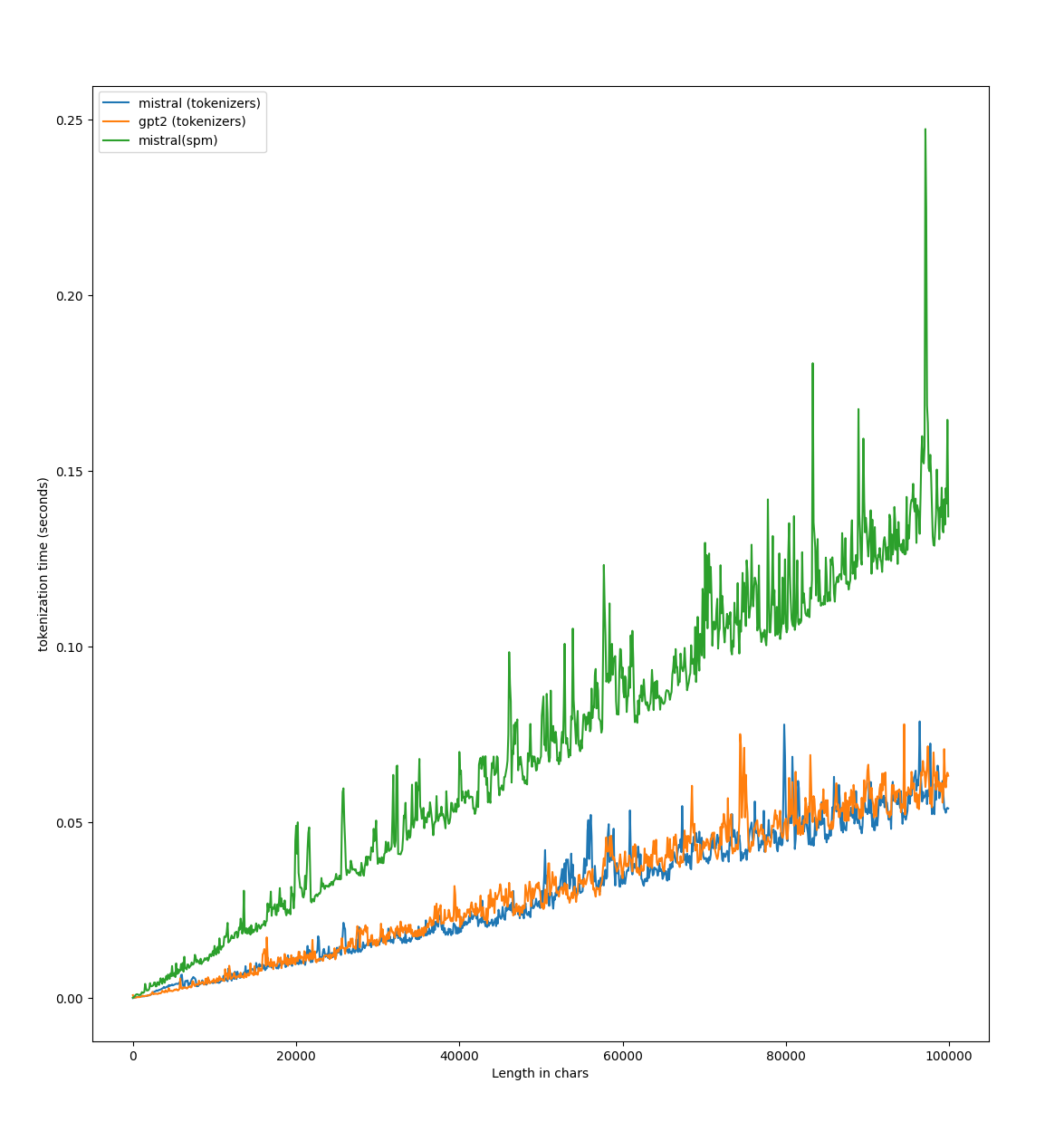
* chore: Update dependencies to latest supported versions by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1441
* Convert word counts to u64 by @stephenroller in https://github.com/huggingface/tokenizers/pull/1433
* Efficient Replace normalizer by @rlrs in https://github.com/huggingface/tokenizers/pull/1413
## New Contributors
* @bryantbiggs made their first contribution in https://github.com/huggingface/tokenizers/pull/1441
* @stephenroller made their first contribution in https://github.com/huggingface/tokenizers/pull/1433
* @rlrs made their first contribution in https://github.com/huggingface/tokenizers/pull/1413
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.1...v0.15.2rc1
## What's Changed
* udpate to version = "0.15.1-dev0" by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1390
* Derive `Clone` on `Tokenizer`, add `Encoding.into_tokens()` method by @epwalsh in https://github.com/huggingface/tokenizers/pull/1381
* Stale bot. by @Narsil in https://github.com/huggingface/tokenizers/pull/1404
* Fix doc links in readme by @Pierrci in https://github.com/huggingface/tokenizers/pull/1367
* Faster HF dataset iteration in docs by @mariosasko in https://github.com/huggingface/tokenizers/pull/1414
* Add quick doc to byte_level.rs by @steventrouble in https://github.com/huggingface/tokenizers/pull/1420
* Fix make bench. by @Narsil in https://github.com/huggingface/tokenizers/pull/1428
* Bump follow-redirects from 1.15.1 to 1.15.4 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1430
* pyo3: update to 0.20 by @mikelui in https://github.com/huggingface/tokenizers/pull/1386
* Encode special tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1437
* Update release for python3.12 windows by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1438
## New Contributors
* @steventrouble made their first contribution in https://github.com/huggingface/tokenizers/pull/1420
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.0...v0.15.1
## What's Changed
* pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322
* Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316
* Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328
* Reduce number of different revisions by 1 by @Narsil in https://github.com/huggingface/tokenizers/pull/1329
* Python 38 arm by @Narsil in https://github.com/huggingface/tokenizers/pull/1330
* Move to maturing mimicking move for `safetensors`. + Rewritten node bindings. by @Narsil in https://github.com/huggingface/tokenizers/pull/1331
* Updating the docs with the new command. by @Narsil in https://github.com/huggingface/tokenizers/pull/1333
* Update added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1335
* update package version for dev by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1339
* Added ability to inspect a 'Sequence' pre-tokenizer. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1341
* Let's allow hf_hub < 1.0 by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1344
* Fixing the progressbar. by @Narsil in https://github.com/huggingface/tokenizers/pull/1353
* Preparing release. by @Narsil in https://github.com/huggingface/tokenizers/pull/1355
* fix a clerical error in the comment by @tiandiweizun in https://github.com/huggingface/tokenizers/pull/1356
* fix: remove useless token by @rtrompier in https://github.com/huggingface/tokenizers/pull/1371
* Bump @babel/traverse from 7.22.11 to 7.23.2 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1370
* Allow hf_hub 0.18 by @mariosasko in https://github.com/huggingface/tokenizers/pull/1383
* Allow `huggingface_hub<1.0` by @Wauplin in https://github.com/huggingface/tokenizers/pull/1385
* [`pre_tokenizers`] Fix sentencepiece based Metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1357
* udpate to version = "0.15.1-dev0" by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1390
* Derive `Clone` on `Tokenizer`, add `Encoding.into_tokens()` method by @epwalsh in https://github.com/huggingface/tokenizers/pull/1381
* Stale bot. by @Narsil in https://github.com/huggingface/tokenizers/pull/1404
* Fix doc links in readme by @Pierrci in https://github.com/huggingface/tokenizers/pull/1367
* Faster HF dataset iteration in docs by @mariosasko in https://github.com/huggingface/tokenizers/pull/1414
* Add quick doc to byte_level.rs by @steventrouble in https://github.com/huggingface/tokenizers/pull/1420
* Fix make bench. by @Narsil in https://github.com/huggingface/tokenizers/pull/1428
* Bump follow-redirects from 1.15.1 to 1.15.4 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1430
* pyo3: update to 0.20 by @mikelui in https://github.com/huggingface/tokenizers/pull/1386
## New Contributors
* @mikelui made their first contribution in https://github.com/huggingface/tokenizers/pull/1322
* @eaplatanios made their first contribution in https://github.com/huggingface/tokenizers/pull/1341
* @tiandiweizun made their first contribution in https://github.com/huggingface/tokenizers/pull/1356
* @rtrompier made their first contribution in https://github.com/huggingface/tokenizers/pull/1371
* @mariosasko made their first contribution in https://github.com/huggingface/tokenizers/pull/1383
* @Wauplin made their first contribution in https://github.com/huggingface/tokenizers/pull/1385
* @steventrouble made their first contribution in https://github.com/huggingface/tokenizers/pull/1420
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.13.4.rc2...v0.15.1.rc0
## What's Changed
* fix a clerical error in the comment by @tiandiweizun in https://github.com/huggingface/tokenizers/pull/1356
* fix: remove useless token by @rtrompier in https://github.com/huggingface/tokenizers/pull/1371
* Bump @babel/traverse from 7.22.11 to 7.23.2 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1370
* Allow hf_hub 0.18 by @mariosasko in https://github.com/huggingface/tokenizers/pull/1383
* Allow `huggingface_hub<1.0` by @Wauplin in https://github.com/huggingface/tokenizers/pull/1385
* [`pre_tokenizers`] Fix sentencepiece based Metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1357
## New Contributors
* @tiandiweizun made their first contribution in https://github.com/huggingface/tokenizers/pull/1356
* @rtrompier made their first contribution in https://github.com/huggingface/tokenizers/pull/1371
* @mariosasko made their first contribution in https://github.com/huggingface/tokenizers/pull/1383
* @Wauplin made their first contribution in https://github.com/huggingface/tokenizers/pull/1385
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.14.1...v0.15.0
Basically good typing with at least `ty`, and a lot fast (from 4 to 8x faster) loading vocab with a lot of added tokens and GIL free !?
* ci: add support for building Win-ARM64 wheels by @MugundanMCW in https://github.com/huggingface/tokenizers/pull/1869
* Add cargo-semver-checks to Rust CI workflow by @haixuanTao in https://github.com/huggingface/tokenizers/pull/1875
* Update indicatif dependency by @gordonmessmer in https://github.com/huggingface/tokenizers/pull/1867
* Bump node-forge from 1.3.1 to 1.3.2 in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1889
* Bump js-yaml from 3.14.1 to 3.14.2 in /bindings/node by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1892
* fix: used normalize_str in BaseTokenizer.normalize by @ishitab02 in https://github.com/huggingface/tokenizers/pull/1884
* [MINOR:TYPO] Update mod.rs by @cakiki in https://github.com/huggingface/tokenizers/pull/1883
* Remove runtime stderr warning from Python bindings by @Copilot in https://github.com/huggingface/tokenizers/pull/1898
* Mark immutable pyclasses as frozen by @ngoldbaum in https://github.com/huggingface/tokenizers/pull/1861
* DOCS: add `add_prefix_space` to `processors.ByteLevel` by @CloseChoice in https://github.com/huggingface/tokenizers/pull/1878
* Bump express from 4.21.2 to 4.22.1 in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1903
## New Contributors
* @MugundanMCW made their first contribution in https://github.com/huggingface/tokenizers/pull/1869
* @haixuanTao made their first contribution in https://github.com/huggingface/tokenizers/pull/1875
* @gordonmessmer made their first contribution in https://github.com/huggingface/tokenizers/pull/1867
* @ishitab02 made their first contribution in https://github.com/huggingface/tokenizers/pull/1884
* @Copilot made their first contribution in https://github.com/huggingface/tokenizers/pull/1898
* @ngoldbaum made their first contribution in https://github.com/huggingface/tokenizers/pull/1861
* @CloseChoice made their first contribution in https://github.com/huggingface/tokenizers/pull/1878
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.22.1...v0.22.2
# Release v0.22.1
Main change:
- Bump huggingface_hub upper version (#1866) from @Wauplin
- chore(trainer): add and improve trainer signature (#1838) from @shenxiangzhuang
- Some doc updates: c91d76ae558ca2dc1aa725959e65dc21bf1fed7e, 7b0217894c1e2baed7354ab41503841b47af7cf9, 57eb8d7d9564621221784f7949b9efdeb7a49ac1
## What's Changed
* Bump on-headers and compression in /tokenizers/examples/unstable_wasm/www by @dependabot[bot] in https://github.com/huggingface/tokenizers/pull/1827
* Implement `from_bytes` and `read_bytes` Methods in WordPiece Tokenizer for WebAssembly Compatibility by @sondalex in https://github.com/huggingface/tokenizers/pull/1758
* fix: use AHashMap to fix compile error by @b00f in https://github.com/huggingface/tokenizers/pull/1840
* New stream by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1856
* [docs] Add more decoders by @pcuenca in https://github.com/huggingface/tokenizers/pull/1849
* Fix missing parenthesis in `EncodingVisualizer.calculate_label_colors` by @Liam-DeVoe in https://github.com/huggingface/tokenizers/pull/1853
* Update quicktour.mdx re: Issue #1625 by @WilliamPLaCroix in https://github.com/huggingface/tokenizers/pull/1846
* remove stray comment by @sanderland in https://github.com/huggingface/tokenizers/pull/1831
* Fix typo in README by @aisk in https://github.com/huggingface/tokenizers/pull/1808
* RUSTSEC-2024-0436 - replace paste with pastey by @nystromjd in https://github.com/huggingface/tokenizers/pull/1834
* Tokenizer: Add native async bindings, via py03-async-runtimes. by @michaelfeil in https://github.com/huggingface/tokenizers/pull/1843
## New Contributors
* @b00f made their first contribution in https://github.com/huggingface/tokenizers/pull/1840
* @pcuenca made their first contribution in https://github.com/huggingface/tokenizers/pull/1849
* @Liam-DeVoe made their first contribution in https://github.com/huggingface/tokenizers/pull/1853
* @WilliamPLaCroix made their first contribution in https://github.com/huggingface/tokenizers/pull/1846
* @sanderland made their first contribution in https://github.com/huggingface/tokenizers/pull/1831
* @aisk made their first contribution in https://github.com/huggingface/tokenizers/pull/1808
* @nystromjd made their first contribution in https://github.com/huggingface/tokenizers/pull/1834
* @michaelfeil made their first contribution in https://github.com/huggingface/tokenizers/pull/1843
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.3...v0.22.0rc0
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.3...v0.21.4
No change, the 0.21.3 release failed, this is just a re-release.
https://github.com/huggingface/tokenizers/releases/tag/v0.21.3
## What's Changed
* Clippy fixes. by @Narsil in https://github.com/huggingface/tokenizers/pull/1818
* Fixed an introduced backward breaking change in our Rust APIs.
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.2...v0.21.3
## What's Changed
This release if focused around some performance optimization, enabling broader python no gil support, and fixing some onig issues!
* Update the release builds following 0.21.1. by @Narsil in https://github.com/huggingface/tokenizers/pull/1746
* replace lazy_static with stabilized std::sync::LazyLock in 1.80 by @sftse in https://github.com/huggingface/tokenizers/pull/1739
* Fix no-onig no-wasm builds by @414owen in https://github.com/huggingface/tokenizers/pull/1772
* Fix typos in strings and comments by @co63oc in https://github.com/huggingface/tokenizers/pull/1770
* Fix type notation of merges in BPE Python binding by @Coqueue in https://github.com/huggingface/tokenizers/pull/1766
* Bump http-proxy-middleware from 2.0.6 to 2.0.9 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1762
* Fix data path in test_continuing_prefix_trainer_mismatch by @GaetanLepage in https://github.com/huggingface/tokenizers/pull/1747
* clippy by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1781
* Update pyo3 and rust-numpy depends for no-gil/free-threading compat by @Qubitium in https://github.com/huggingface/tokenizers/pull/1774
* Use ApiBuilder::from_env() in from_pretrained function by @BenLocal in https://github.com/huggingface/tokenizers/pull/1737
* Upgrade onig, to get it compiling with GCC 15 by @414owen in https://github.com/huggingface/tokenizers/pull/1771
* Itertools upgrade by @sftse in https://github.com/huggingface/tokenizers/pull/1756
* Bump webpack-dev-server from 4.10.0 to 5.2.1 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1792
* Bump brace-expansion from 1.1.11 to 1.1.12 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1796
* Fix features blending into a paragraph by @bionicles in https://github.com/huggingface/tokenizers/pull/1798
* Adding throughput to benches to have a more consistent measure across by @Narsil in https://github.com/huggingface/tokenizers/pull/1800
* Upgrading dependencies. by @Narsil in https://github.com/huggingface/tokenizers/pull/1801
* [docs] Whitespace by @stevhliu in https://github.com/huggingface/tokenizers/pull/1785
* Hotfixing the stub. by @Narsil in https://github.com/huggingface/tokenizers/pull/1802
* Bpe clones by @sftse in https://github.com/huggingface/tokenizers/pull/1707
* Fixed Length Pre-Tokenizer by @jonvet in https://github.com/huggingface/tokenizers/pull/1713
* Consolidated optimization ahash dary compact str by @Narsil in https://github.com/huggingface/tokenizers/pull/1799
* 🚨 breaking: Fix training with special tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1617
## New Contributors
* @414owen made their first contribution in https://github.com/huggingface/tokenizers/pull/1772
* @co63oc made their first contribution in https://github.com/huggingface/tokenizers/pull/1770
* @Coqueue made their first contribution in https://github.com/huggingface/tokenizers/pull/1766
* @GaetanLepage made their first contribution in https://github.com/huggingface/tokenizers/pull/1747
* @Qubitium made their first contribution in https://github.com/huggingface/tokenizers/pull/1774
* @BenLocal made their first contribution in https://github.com/huggingface/tokenizers/pull/1737
* @bionicles made their first contribution in https://github.com/huggingface/tokenizers/pull/1798
* @stevhliu made their first contribution in https://github.com/huggingface/tokenizers/pull/1785
* @jonvet made their first contribution in https://github.com/huggingface/tokenizers/pull/1713
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.1...v0.21.2rc0
## What's Changed
* Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693
* Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709
* Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708
* Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714
* Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/huggingface/tokenizers/pull/1701
* Fix typos by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1715
* Update documentation of Rust feature by @sondalex in https://github.com/huggingface/tokenizers/pull/1711
* Fix panic in DecodeStream::step due to incorrect index usage by @n0gu-furiosa in https://github.com/huggingface/tokenizers/pull/1699
* Fixing the stream by removing the read_index altogether. by @Narsil in https://github.com/huggingface/tokenizers/pull/1716
* Fixing NormalizedString append when normalized is empty. by @Narsil in https://github.com/huggingface/tokenizers/pull/1717
* 🚨 Support updating template processors by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1652. Removed in this release to keep backware compatibility temporarily.
* Update metadata as Python3.7 and Python3.8 support was dropped by @earlytobed in https://github.com/huggingface/tokenizers/pull/1724
* Add rustls-tls feature by @torymur in https://github.com/huggingface/tokenizers/pull/1732
## New Contributors
* @Dylan-Harden3 made their first contribution in https://github.com/huggingface/tokenizers/pull/1701
* @sondalex made their first contribution in https://github.com/huggingface/tokenizers/pull/1711
* @n0gu-furiosa made their first contribution in https://github.com/huggingface/tokenizers/pull/1699
* @earlytobed made their first contribution in https://github.com/huggingface/tokenizers/pull/1724
* @torymur made their first contribution in https://github.com/huggingface/tokenizers/pull/1732
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.0...v0.21.1
## What's Changed
* Update dev version and pyproject.toml by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1693
* Add feature flag hint to README.md, fixes #1633 by @sftse in https://github.com/huggingface/tokenizers/pull/1709
* Upgrade to PyO3 0.23 by @Narsil in https://github.com/huggingface/tokenizers/pull/1708
* Fixing the README. by @Narsil in https://github.com/huggingface/tokenizers/pull/1714
* Fix typo in Split docstrings by @Dylan-Harden3 in https://github.com/huggingface/tokenizers/pull/1701
* Fix typos by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1715
* Update documentation of Rust feature by @sondalex in https://github.com/huggingface/tokenizers/pull/1711
* Fix panic in DecodeStream::step due to incorrect index usage by @n0gu-furiosa in https://github.com/huggingface/tokenizers/pull/1699
* Fixing the stream by removing the read_index altogether. by @Narsil in https://github.com/huggingface/tokenizers/pull/1716
* Fixing NormalizedString append when normalized is empty. by @Narsil in https://github.com/huggingface/tokenizers/pull/1717
* 🚨 Support updating template processors by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1652
* Update metadata as Python3.7 and Python3.8 support was dropped by @earlytobed in https://github.com/huggingface/tokenizers/pull/1724
* Add rustls-tls feature by @torymur in https://github.com/huggingface/tokenizers/pull/1732
## New Contributors
* @Dylan-Harden3 made their first contribution in https://github.com/huggingface/tokenizers/pull/1701
* @sondalex made their first contribution in https://github.com/huggingface/tokenizers/pull/1711
* @n0gu-furiosa made their first contribution in https://github.com/huggingface/tokenizers/pull/1699
* @earlytobed made their first contribution in https://github.com/huggingface/tokenizers/pull/1724
* @torymur made their first contribution in https://github.com/huggingface/tokenizers/pull/1732
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.21.0...v0.21.1rc0
## Release v0.21.0
## Release ~v0.20.4~ v0.21.0
* More cache options. by @Narsil in https://github.com/huggingface/tokenizers/pull/1675
* Disable caching for long strings. by @Narsil in https://github.com/huggingface/tokenizers/pull/1676
* Testing ABI3 wheels to reduce number of wheels by @Narsil in https://github.com/huggingface/tokenizers/pull/1674
* Adding an API for decode streaming. by @Narsil in https://github.com/huggingface/tokenizers/pull/1677
* Decode stream python by @Narsil in https://github.com/huggingface/tokenizers/pull/1678
* Fix encode_batch and encode_batch_fast to accept ndarrays again by @diliop in https://github.com/huggingface/tokenizers/pull/1679
We also no longer support python 3.7 or 3.8 (similar to transformers) as they are deprecated.
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.3...v0.21.0
## What's Changed
There was a breaking change in `0.20.3` for tuple inputs of `encode_batch`!
* fix pylist by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1673
* [MINOR:TYPO] Fix docstrings by @cakiki in https://github.com/huggingface/tokenizers/pull/1653
## New Contributors
* @cakiki made their first contribution in https://github.com/huggingface/tokenizers/pull/1653
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.2...v0.20.3
# Release v0.20.2
Thanks a MILE to @diliop we now have support for python 3.13! 🥳
## What's Changed
* Bump cookie and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1648
* Fix off-by-one error in tokenizer::normalizer::Range::len by @rlanday in https://github.com/huggingface/tokenizers/pull/1638
* Arg name correction: auth_token -> token by @rravenel in https://github.com/huggingface/tokenizers/pull/1621
* Unsound call of `set_var` by @sftse in https://github.com/huggingface/tokenizers/pull/1664
* Add safety comments by @Manishearth in https://github.com/huggingface/tokenizers/pull/1651
* Bump actions/checkout to v4 by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1667
* PyO3 0.22 by @diliop in https://github.com/huggingface/tokenizers/pull/1665
* Bump actions versions by @tinyboxvk in https://github.com/huggingface/tokenizers/pull/1669
## New Contributors
* @rlanday made their first contribution in https://github.com/huggingface/tokenizers/pull/1638
* @rravenel made their first contribution in https://github.com/huggingface/tokenizers/pull/1621
* @sftse made their first contribution in https://github.com/huggingface/tokenizers/pull/1664
* @Manishearth made their first contribution in https://github.com/huggingface/tokenizers/pull/1651
* @tinyboxvk made their first contribution in https://github.com/huggingface/tokenizers/pull/1667
* @diliop made their first contribution in https://github.com/huggingface/tokenizers/pull/1665
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.1...v0.20.2
## Release v0.20.1
## What's Changed
The most awaited `offset` issue with `Llama` is fixed 🥳
* Update README.md by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1608
* fix benchmark file link by @152334H in https://github.com/huggingface/tokenizers/pull/1610
* Bump actions/download-artifact from 3 to 4.1.7 in /.github/workflows by @dependabot in https://github.com/huggingface/tokenizers/pull/1626
* [`ignore_merges`] Fix offsets by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1640
* Bump body-parser and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1629
* Bump serve-static and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1630
* Bump send and express in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1631
* Bump webpack from 5.76.0 to 5.95.0 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1641
* Fix documentation build by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1642
* style: simplify string formatting for readability by @hamirmahal in https://github.com/huggingface/tokenizers/pull/1632
## New Contributors
* @152334H made their first contribution in https://github.com/huggingface/tokenizers/pull/1610
* @hamirmahal made their first contribution in https://github.com/huggingface/tokenizers/pull/1632
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.20.0...v0.20.1
## Release v0.20.0: faster encode, better python support
# Release v0.20.0
This release is focused on **performances** and **user experience**.
## Performances:
First off, we did a bit of benchmarking, and found some place for improvement for us!
With a few minor changes (mostly #1587) here is what we get on `Llama3` running on a g6 instances on AWS `https://github.com/huggingface/tokenizers/blob/main/bindings/python/benches/test_tiktoken.py` :

## Python API
We shipped better deserialization errors in general, and support for `__str__` and `__repr__` for all the object. This allows for a lot easier debugging see this:
```python3
>>> from tokenizers import Tokenizer;
>>> tokenizer = Tokenizer.from_pretrained("bert-base-uncased");
>>> print(tokenizer)
Tokenizer(version="1.0", truncation=None, padding=None, added_tokens=[{"id":0, "content":"[PAD]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":100, "content":"[UNK]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":101, "content":"[CLS]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":102, "content":"[SEP]", "single_word":False, "lstrip":False, "rstrip":False, ...}, {"id":103, "content":"[MASK]", "single_word":False, "lstrip":False, "rstrip":False, ...}], normalizer=BertNormalizer(clean_text=True, handle_chinese_chars=True, strip_accents=None, lowercase=True), pre_tokenizer=BertPreTokenizer(), post_processor=TemplateProcessing(single=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0)], pair=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0), Sequence(id=B, type_id=1), SpecialToken(id="[SEP]", type_id=1)], special_tokens={"[CLS]":SpecialToken(id="[CLS]", ids=[101], tokens=["[CLS]"]), "[SEP]":SpecialToken(id="[SEP]", ids=[102], tokens=["[SEP]"])}), decoder=WordPiece(prefix="##", cleanup=True), model=WordPiece(unk_token="[UNK]", continuing_subword_prefix="##", max_input_chars_per_word=100, vocab={"[PAD]":0, "[unused0]":1, "[unused1]":2, "[unused2]":3, "[unused3]":4, ...}))
>>> tokenizer
Tokenizer(version="1.0", truncation=None, padding=None, added_tokens=[{"id":0, "content":"[PAD]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":100, "content":"[UNK]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":101, "content":"[CLS]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":102, "content":"[SEP]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}, {"id":103, "content":"[MASK]", "single_word":False, "lstrip":False, "rstrip":False, "normalized":False, "special":True}], normalizer=BertNormalizer(clean_text=True, handle_chinese_chars=True, strip_accents=None, lowercase=True), pre_tokenizer=BertPreTokenizer(), post_processor=TemplateProcessing(single=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0)], pair=[SpecialToken(id="[CLS]", type_id=0), Sequence(id=A, type_id=0), SpecialToken(id="[SEP]", type_id=0), Sequence(id=B, type_id=1), SpecialToken(id="[SEP]", type_id=1)], special_tokens={"[CLS]":SpecialToken(id="[CLS]", ids=[101], tokens=["[CLS]"]), "[SEP]":SpecialToken(id="[SEP]", ids=[102], tokens=["[SEP]"])}), decoder=WordPiece(prefix="##", cleanup=True), model=WordPiece(unk_token="[UNK]", continuing_subword_prefix="##", max_input_chars_per_word=100, vocab={"[PAD]":0, "[unused0]":1, "[unused1]":2, ...}))
```
The `pre_tokenizer.Sequence` and `normalizer.Sequence` are also more accessible now:
```python
from tokenizers import normalizers
norm = normalizers.Sequence([normalizers.Strip(), normalizers.BertNormalizer()])
norm[0]
norm[1].lowercase=False
```
## What's Changed
* remove enforcement of non special when adding tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1521
* [BREAKING CHANGE] Ignore added_tokens (both special and not) in the decoder by @Narsil in https://github.com/huggingface/tokenizers/pull/1513
* Make `USED_PARALLELISM` atomic by @nathaniel-daniel in https://github.com/huggingface/tokenizers/pull/1532
* Fixing for clippy 1.78 by @Narsil in https://github.com/huggingface/tokenizers/pull/1548
* feat(ci): add trufflehog secrets detection by @McPatate in https://github.com/huggingface/tokenizers/pull/1551
* Switch from `cached_download` to `hf_hub_download` in tests by @Wauplin in https://github.com/huggingface/tokenizers/pull/1547
* Fix "dictionnary" typo by @nprisbrey in https://github.com/huggingface/tokenizers/pull/1511
* make sure we don't warn on empty tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1554
* Enable `dropout = 0.0` as an equivalent to `none` in BPE by @mcognetta in https://github.com/huggingface/tokenizers/pull/1550
* Revert "[BREAKING CHANGE] Ignore added_tokens (both special and not) … by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1569
* Add bytelevel normalizer to fix decode when adding tokens to BPE by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1555
* Fix clippy + feature test management. by @Narsil in https://github.com/huggingface/tokenizers/pull/1580
* Bump spm_precompiled to 0.1.3 by @MikeIvanichev in https://github.com/huggingface/tokenizers/pull/1571
* Add benchmark vs tiktoken by @Narsil in https://github.com/huggingface/tokenizers/pull/1582
* Fixing the benchmark. by @Narsil in https://github.com/huggingface/tokenizers/pull/1583
* Tiny improvement by @Narsil in https://github.com/huggingface/tokenizers/pull/1585
* Enable fancy regex by @Narsil in https://github.com/huggingface/tokenizers/pull/1586
* Fixing release CI strict (taken from safetensors). by @Narsil in https://github.com/huggingface/tokenizers/pull/1593
* Adding some serialization testing around the wrapper. by @Narsil in https://github.com/huggingface/tokenizers/pull/1594
* Add-legacy-tests by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1597
* Adding a few tests for decoder deserialization. by @Narsil in https://github.com/huggingface/tokenizers/pull/1598
* Better serialization error by @Narsil in https://github.com/huggingface/tokenizers/pull/1595
* Add test normalizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1600
* Improve decoder deserialization by @Narsil in https://github.com/huggingface/tokenizers/pull/1599
* Using serde (serde_pyo3) to get __str__ and __repr__ easily. by @Narsil in https://github.com/huggingface/tokenizers/pull/1588
* Merges cannot handle tokens containing spaces. by @Narsil in https://github.com/huggingface/tokenizers/pull/909
* Fix doc about split by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1591
* Support `None` to reset pre_tokenizers and normalizers, and index sequences by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1590
* Fix strip python type by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1602
* Tests + Deserialization improvement for normalizers. by @Narsil in https://github.com/huggingface/tokenizers/pull/1604
* add deserialize for pre tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1603
* Perf improvement 16% by removing offsets. by @Narsil in https://github.com/huggingface/tokenizers/pull/1587
## New Contributors
* @nathaniel-daniel made their first contribution in https://github.com/huggingface/tokenizers/pull/1532
* @nprisbrey made their first contribution in https://github.com/huggingface/tokenizers/pull/1511
* @mcognetta made their first contribution in https://github.com/huggingface/tokenizers/pull/1550
* @MikeIvanichev made their first contribution in https://github.com/huggingface/tokenizers/pull/1571
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.19.1...v0.20.0rc1
## What's Changed
* add serialization for `ignore_merges` by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1504
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.19.0...v0.19.1
## What's Changed
* chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442
* [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436
* Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1456
* Added ability to inspect a 'Sequence' decoder and the `AddedVocabulary`. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1443
* 🚨🚨 BREAKING CHANGE 🚨🚨: (add_prefix_space dropped everything is using prepend_scheme enum instead) Refactor metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1476
* Add more support for tiktoken based tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1493
* PyO3 0.21. by @Narsil in https://github.com/huggingface/tokenizers/pull/1494
* Remove 3.13 (potential undefined behavior.) by @Narsil in https://github.com/huggingface/tokenizers/pull/1497
* Bumping all versions 3 times (ty transformers :) ) by @Narsil in https://github.com/huggingface/tokenizers/pull/1498
* Fixing doc. by @Narsil in https://github.com/huggingface/tokenizers/pull/1499
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.2...v0.19.0
Bumping 3 versions because of this: https://github.com/huggingface/transformers/blob/60dea593edd0b94ee15dc3917900b26e3acfbbee/setup.py#L177
## What's Changed
* chore: Remove CLI - this was originally intended for local development by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1442
* [`remove black`] And use ruff by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1436
* Bump ip from 2.0.0 to 2.0.1 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1456
* Added ability to inspect a 'Sequence' decoder and the `AddedVocabulary`. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1443
* 🚨🚨 BREAKING CHANGE 🚨🚨: (add_prefix_space dropped everything is using prepend_scheme enum instead) Refactor metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1476
* Add more support for tiktoken based tokenizers by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1493
* PyO3 0.21. by @Narsil in https://github.com/huggingface/tokenizers/pull/1494
* Remove 3.13 (potential undefined behavior.) by @Narsil in https://github.com/huggingface/tokenizers/pull/1497
* Bumping all versions 3 times (ty transformers :) ) by @Narsil in https://github.com/huggingface/tokenizers/pull/1498
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.2...v0.19.0rc0
## What's Changed
Big shoutout to @rlrs for [the fast replace normalizers](https://github.com/huggingface/tokenizers/pull/1413) PR. This boosts the performances of the tokenizers:

* chore: Update dependencies to latest supported versions by @bryantbiggs in https://github.com/huggingface/tokenizers/pull/1441
* Convert word counts to u64 by @stephenroller in https://github.com/huggingface/tokenizers/pull/1433
* Efficient Replace normalizer by @rlrs in https://github.com/huggingface/tokenizers/pull/1413
## New Contributors
* @bryantbiggs made their first contribution in https://github.com/huggingface/tokenizers/pull/1441
* @stephenroller made their first contribution in https://github.com/huggingface/tokenizers/pull/1433
* @rlrs made their first contribution in https://github.com/huggingface/tokenizers/pull/1413
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.1...v0.15.2rc1
## What's Changed
* udpate to version = "0.15.1-dev0" by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1390
* Derive `Clone` on `Tokenizer`, add `Encoding.into_tokens()` method by @epwalsh in https://github.com/huggingface/tokenizers/pull/1381
* Stale bot. by @Narsil in https://github.com/huggingface/tokenizers/pull/1404
* Fix doc links in readme by @Pierrci in https://github.com/huggingface/tokenizers/pull/1367
* Faster HF dataset iteration in docs by @mariosasko in https://github.com/huggingface/tokenizers/pull/1414
* Add quick doc to byte_level.rs by @steventrouble in https://github.com/huggingface/tokenizers/pull/1420
* Fix make bench. by @Narsil in https://github.com/huggingface/tokenizers/pull/1428
* Bump follow-redirects from 1.15.1 to 1.15.4 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1430
* pyo3: update to 0.20 by @mikelui in https://github.com/huggingface/tokenizers/pull/1386
* Encode special tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1437
* Update release for python3.12 windows by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1438
## New Contributors
* @steventrouble made their first contribution in https://github.com/huggingface/tokenizers/pull/1420
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.15.0...v0.15.1
## What's Changed
* pyo3: update to 0.19 by @mikelui in https://github.com/huggingface/tokenizers/pull/1322
* Add `expect()` for disabling truncation by @boyleconnor in https://github.com/huggingface/tokenizers/pull/1316
* Re-using scritpts from safetensors. by @Narsil in https://github.com/huggingface/tokenizers/pull/1328
* Reduce number of different revisions by 1 by @Narsil in https://github.com/huggingface/tokenizers/pull/1329
* Python 38 arm by @Narsil in https://github.com/huggingface/tokenizers/pull/1330
* Move to maturing mimicking move for `safetensors`. + Rewritten node bindings. by @Narsil in https://github.com/huggingface/tokenizers/pull/1331
* Updating the docs with the new command. by @Narsil in https://github.com/huggingface/tokenizers/pull/1333
* Update added tokens by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1335
* update package version for dev by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1339
* Added ability to inspect a 'Sequence' pre-tokenizer. by @eaplatanios in https://github.com/huggingface/tokenizers/pull/1341
* Let's allow hf_hub < 1.0 by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1344
* Fixing the progressbar. by @Narsil in https://github.com/huggingface/tokenizers/pull/1353
* Preparing release. by @Narsil in https://github.com/huggingface/tokenizers/pull/1355
* fix a clerical error in the comment by @tiandiweizun in https://github.com/huggingface/tokenizers/pull/1356
* fix: remove useless token by @rtrompier in https://github.com/huggingface/tokenizers/pull/1371
* Bump @babel/traverse from 7.22.11 to 7.23.2 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1370
* Allow hf_hub 0.18 by @mariosasko in https://github.com/huggingface/tokenizers/pull/1383
* Allow `huggingface_hub<1.0` by @Wauplin in https://github.com/huggingface/tokenizers/pull/1385
* [`pre_tokenizers`] Fix sentencepiece based Metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1357
* udpate to version = "0.15.1-dev0" by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1390
* Derive `Clone` on `Tokenizer`, add `Encoding.into_tokens()` method by @epwalsh in https://github.com/huggingface/tokenizers/pull/1381
* Stale bot. by @Narsil in https://github.com/huggingface/tokenizers/pull/1404
* Fix doc links in readme by @Pierrci in https://github.com/huggingface/tokenizers/pull/1367
* Faster HF dataset iteration in docs by @mariosasko in https://github.com/huggingface/tokenizers/pull/1414
* Add quick doc to byte_level.rs by @steventrouble in https://github.com/huggingface/tokenizers/pull/1420
* Fix make bench. by @Narsil in https://github.com/huggingface/tokenizers/pull/1428
* Bump follow-redirects from 1.15.1 to 1.15.4 in /tokenizers/examples/unstable_wasm/www by @dependabot in https://github.com/huggingface/tokenizers/pull/1430
* pyo3: update to 0.20 by @mikelui in https://github.com/huggingface/tokenizers/pull/1386
## New Contributors
* @mikelui made their first contribution in https://github.com/huggingface/tokenizers/pull/1322
* @eaplatanios made their first contribution in https://github.com/huggingface/tokenizers/pull/1341
* @tiandiweizun made their first contribution in https://github.com/huggingface/tokenizers/pull/1356
* @rtrompier made their first contribution in https://github.com/huggingface/tokenizers/pull/1371
* @mariosasko made their first contribution in https://github.com/huggingface/tokenizers/pull/1383
* @Wauplin made their first contribution in https://github.com/huggingface/tokenizers/pull/1385
* @steventrouble made their first contribution in https://github.com/huggingface/tokenizers/pull/1420
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.13.4.rc2...v0.15.1.rc0
## What's Changed
* fix a clerical error in the comment by @tiandiweizun in https://github.com/huggingface/tokenizers/pull/1356
* fix: remove useless token by @rtrompier in https://github.com/huggingface/tokenizers/pull/1371
* Bump @babel/traverse from 7.22.11 to 7.23.2 in /bindings/node by @dependabot in https://github.com/huggingface/tokenizers/pull/1370
* Allow hf_hub 0.18 by @mariosasko in https://github.com/huggingface/tokenizers/pull/1383
* Allow `huggingface_hub<1.0` by @Wauplin in https://github.com/huggingface/tokenizers/pull/1385
* [`pre_tokenizers`] Fix sentencepiece based Metaspace by @ArthurZucker in https://github.com/huggingface/tokenizers/pull/1357
## New Contributors
* @tiandiweizun made their first contribution in https://github.com/huggingface/tokenizers/pull/1356
* @rtrompier made their first contribution in https://github.com/huggingface/tokenizers/pull/1371
* @mariosasko made their first contribution in https://github.com/huggingface/tokenizers/pull/1383
* @Wauplin made their first contribution in https://github.com/huggingface/tokenizers/pull/1385
**Full Changelog**: https://github.com/huggingface/tokenizers/compare/v0.14.1...v0.15.0